Go实时GC——三色算法理论与实践
对于实时系统而言,垃圾回收系统可能是一个极大的隐患,因为在垃圾回收的时候需要将整个程序暂停。所以在我们设计消息总线系统的时候,需要小心地选择我们的语言。Go一直在强调它的低延迟,但是它真的做到了吗?如果是的,它是怎么做到的呢?
在这篇文章当中,我们将会看到Go语言的GC是如何实现的(tricolor algorithm,三色算法),以及为什么这种方法能够达到如此之低的GC暂停,以及最重要的是,它是否真的有效(对这些GC暂停进行benchmar测试,以及同其它类型的语言进行比较)。
From Haskell to Go
我们用pub/sub消息总线系统为例说明问题,这些系统在发布消息的时候都是in-memory存储的。在早期,我们用Haskell实现了第一版的消息系统,但是后面发现GHC的gabage collector存在一些基础延迟的问题,我们放弃了这个系统转而用Go进行了实现。
这是我们有关Haskell消息系统的一些实现细节,在GHC中最重要的一点是它GC暂停时间同当前的工作集的大小成比例关系(也就是说,GC时间和内存中存储对象的数目有关)。在我们的例子中,内存中存储对象的数目往往都非常巨大,这就导致gc时间常常高达数百毫秒。这就会导致在GC的时候整个系统是阻塞的。
而在Go语言中,不同于GHC的全局暂停(stop-the-world)收集器,Go的垃圾收集器是和主程序并行的。这就可以避免程序的长时间暂停。我们则更加关注于Go所承诺的低延迟以及其在每个新版本中所提及的延迟提升是否真的向他们所说的那样。
并行垃圾回收是如何工作的?
Go的GC是如何实现并行的呢?其中的关键在于tricolor mark-and-sweep algorithm 三色标记清除算法。该算法能够让系统的gc暂停时间成为能够预测的问题。调度器能够在很短的时间内实现GC调度,并且对源程序的影响极小。下面我们看看三色标记清除算法是如何工作的:
假设我们有这样的一段链表操作的代码:
var A LinkedListNode;
var B LinkedListNode;
// ...
B.next = &LinkedListNode{next: nil};
// ...
A.next = &LinkedListNode{next: nil};
*(B.next).next = &LinkedListNode{next: nil};
B.next = *(B.next).next;
B.next = nil;
第一步
var A LinkedListNode;
var B LinkedListNode;
// ...
B.next = &LinkedListNode{next: nil};
刚开始我们假设有三个节点A、B和C,作为根节点,红色的节点A和B始终都能够被访问到,然后进行一次赋值B.next = &C。初始的时候垃圾收集器有三个集合,分别为黑色,灰色和白色。现在,因为垃圾收集器还没有运行起来,所以三个节点都在白色集合中。
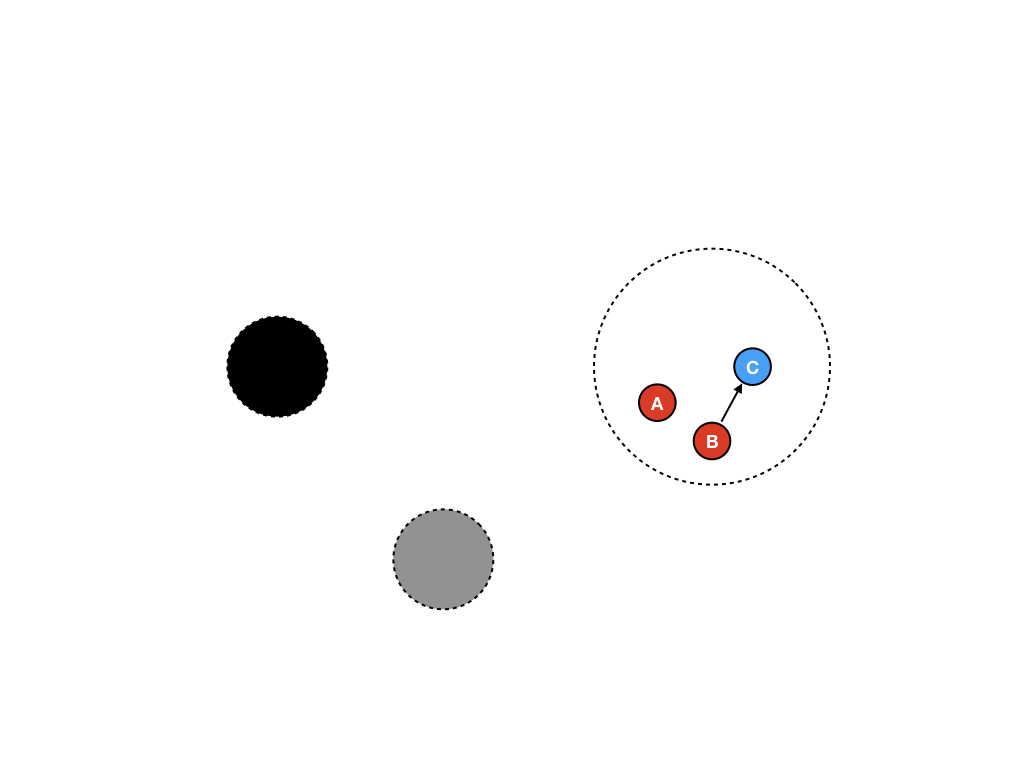
第二步
我们新建一个节点D,并将其赋值给A.next。即:
var A LinkedListNode;
var B LinkedListNode;
// ...
B.next = &LinkedListNode{next: nil};
// ...
A.next = &LinkedListNode{next: nil};
需要注意的是,作为一个新的内存对象,需要将其放置在灰色区域中。为什么要将其放在灰色区域中呢?这里有一个规则,如果一个指针域发生了变化,则被指向的对象需要变色。因为所有的新建内存对象都需要将其地址赋值给一个引用,所以他们将会立即变为灰色。(这就需要问了,为什么C不是灰色?)
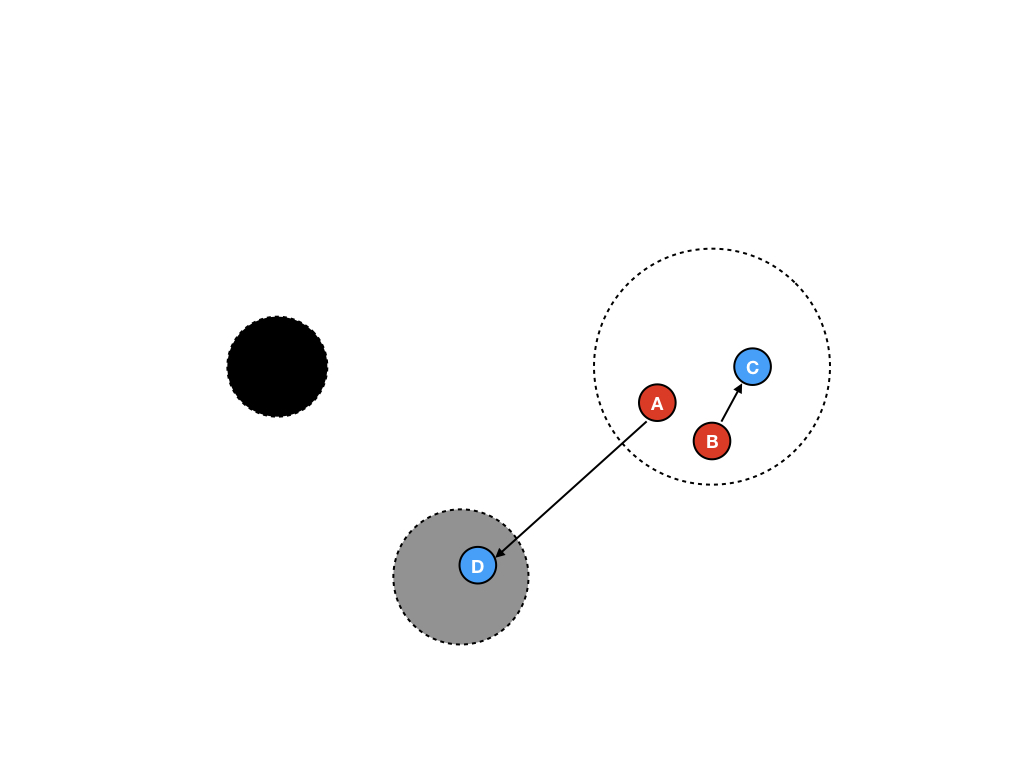
第三步
在开始GC的时候,根节点将会被移入灰色区域。此时A、B、D三个节点都在灰色区域中。由于所有的程序子过程(process,因为不能说是进程,应该算是线程,但是在go中又不完全是线程)要么事程序正常逻辑,要么是GC的过程,而且GC和程序逻辑是并行的,所以程序逻辑和GC过程应该是交替占用CPU资源的。

第四步 扫描内存对象
在扫描内存对象的时候,GC收集器将会把该内存对象标记为黑色,然后将其子内存对象标记为灰色。在任一阶段,我们都能够计算当前GC收集器需要进行的移动步数:2*|white| + |grey|,在每一次扫描GC收集器都至少进行一次移动,直到达到当前灰色区域内存对象数目为0。

第五步
程序此时的逻辑为,新赋值一个内存对象E给C.next,代码如下:
var A LinkedListNode;
var B LinkedListNode;
// ...
B.next = &LinkedListNode{next: nil};
// ...
A.next = &LinkedListNode{next: nil};
//新赋值 C.next = &E
*(B.next).next = &LinkedListNode{next: nil};
按照我们之前的规则,新建的内存对象需要放置在灰色区域,如图所示:
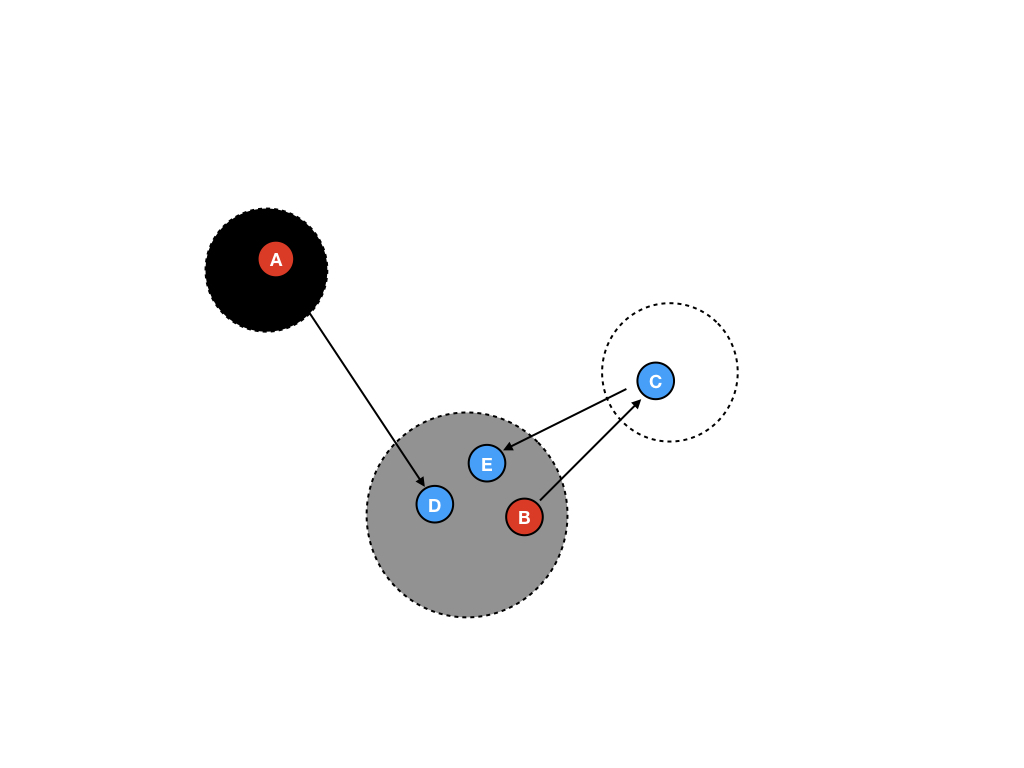
这样做,收集器需要做更多的事情,但是这样做当在新建很多内存对象的时候,可以将最终的清除操作延迟。值得一提的是,这样处理白色区域的体积将会减小,直到收集器真正清理堆空间时再重新填入移入新的内存对象。
第六步 指针重新赋值
程序逻辑此时将 B.next.next赋值给了B.next,也就是将E赋值给了B.next。代码如下:
var A LinkedListNode;
var B LinkedListNode;
// ...
B.next = &LinkedListNode{next: nil};
// ...
A.next = &LinkedListNode{next: nil};
*(B.next).next = &LinkedListNode{next: nil};
// 指针重新赋值:
B.next = *(B.next).next;
这样做之后,如图所示,C将不可达。
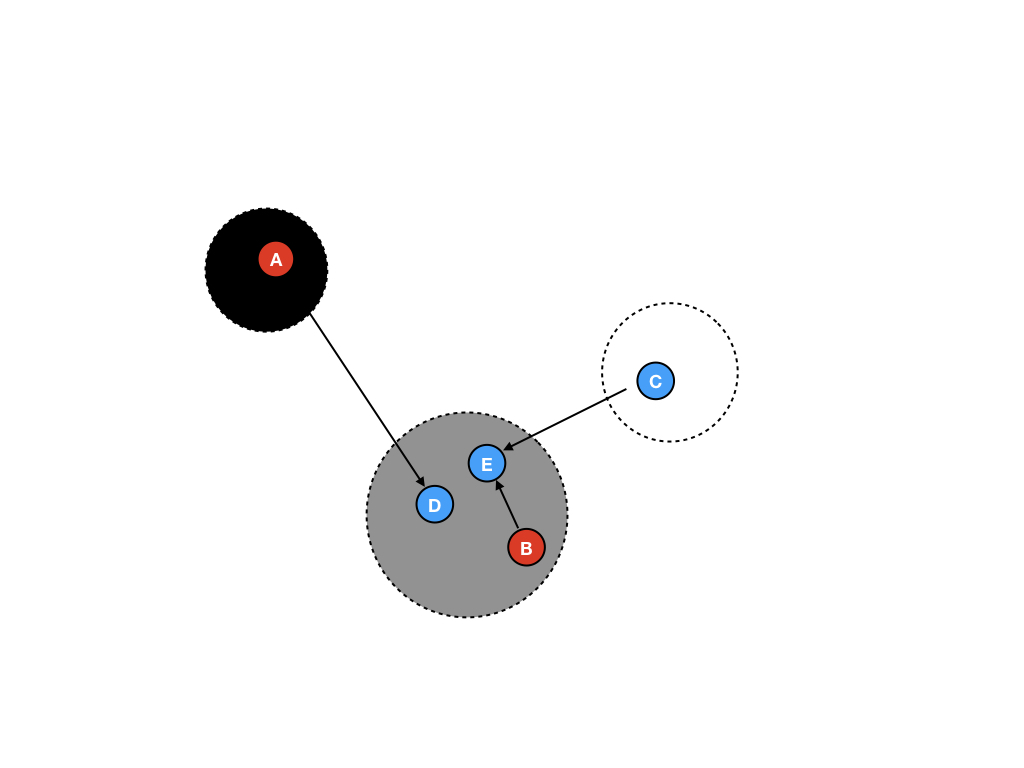
这就意味着,收集器需要将C从白色区域移除,然后在GC循环中将其占用的内存空间回收。
第七步
将灰色区域中没有引用依赖的内存对象移动到黑色区域中,此时D在灰色区域中没有其它依赖,并依赖于它的内存对象A已经在黑色区域了,将其移动到黑色区域中。
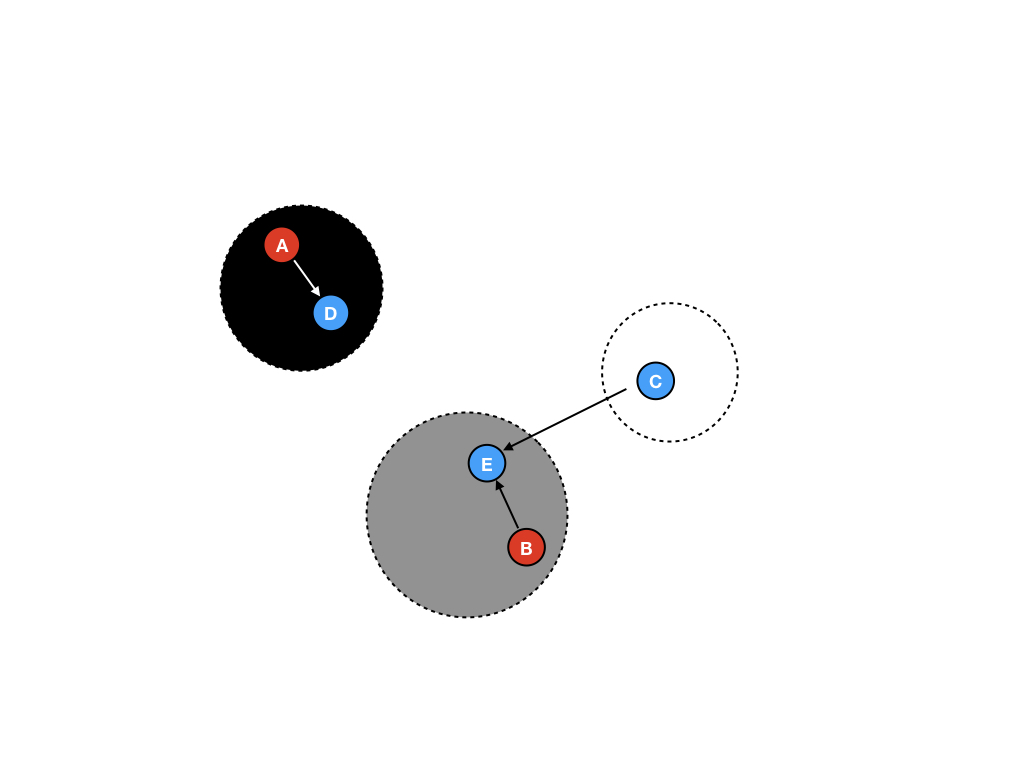
第八步
在程序逻辑中,将B.next赋值为了nil,此时E将变为不可达。但此时E在灰色区域,将不会被回收,那么这样会导致内存泄漏吗?其实不会,E将在下一个GC循环中被回收,三色算法能够保证这点:如果一个内存对象在一次GC循环开始的时候无法被访问,则将会被冻结,并在GC的最后将其回收。
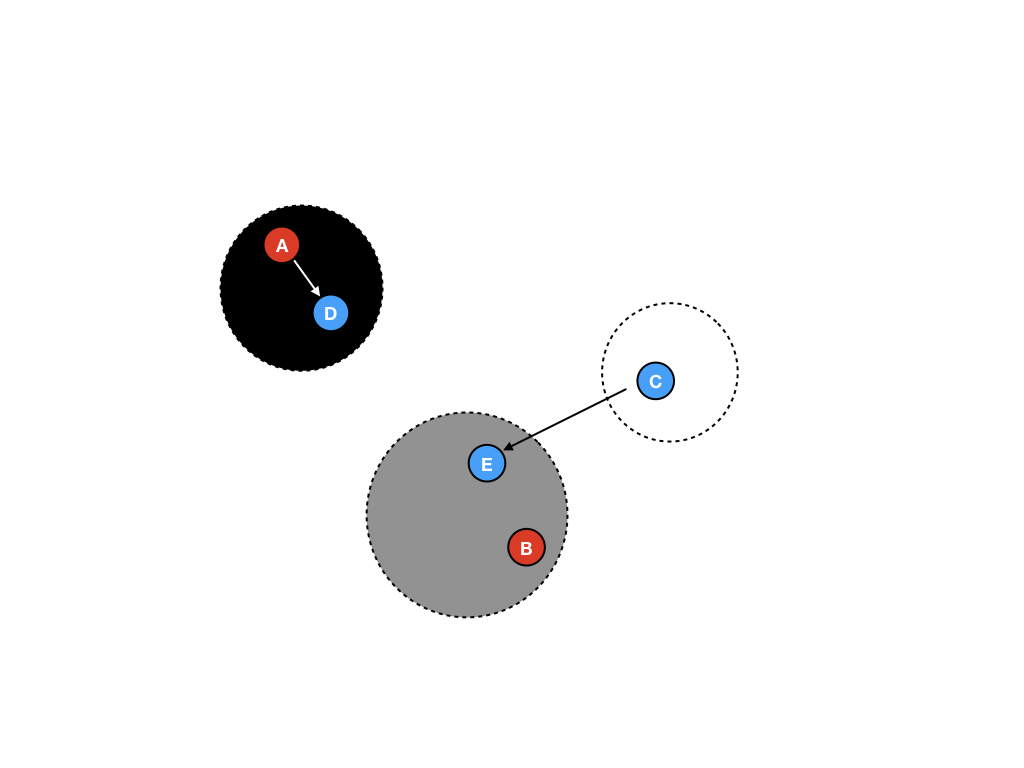
第九步
在进行第二次GC循环的时候,将E移入到黑色区域,但是C并不会移动,因为是C引用了E,而不是E引用C。
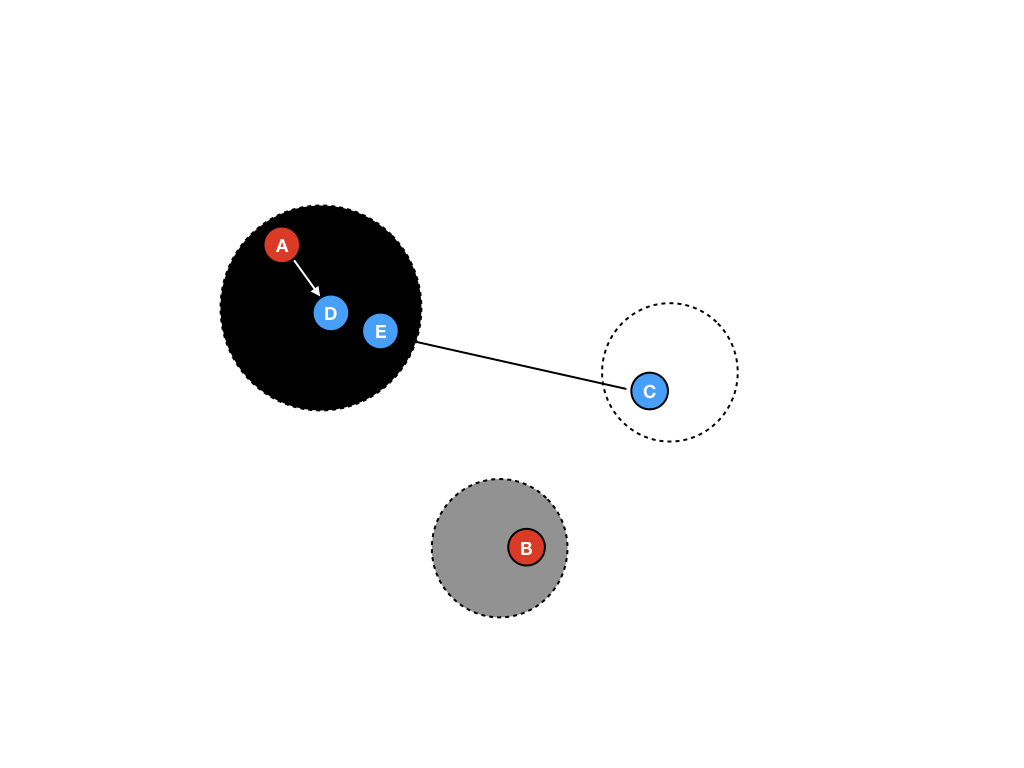
第十步
收集器再扫描最后一个灰色区域中的内存对象B,并将其移动到黑色区域中。

第十一步 回收白色区域
现在灰色区域已经没有内存对象了,这个时候就将白色区域中的内存对象回收。在这个阶段,收集器已经知道白色区域的内存对象已经没有任何引用且不可访问了,就将其当做垃圾进行回收。而在这个阶段,E不会被回收,因为这个循环中,E才刚刚变为不可达,它将在下个循环中被回收。
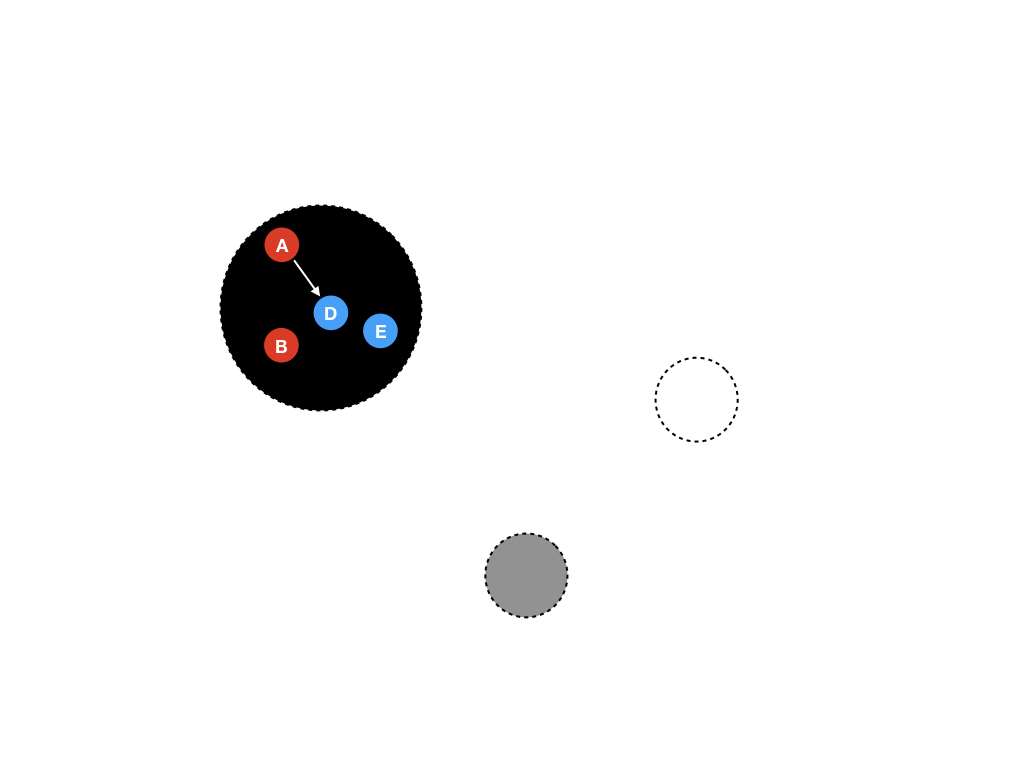
第十二步 区域变色
这一步是最有趣的,在进行下次GC循环的时候,完全不需要将所有的内存对象移动回白色区域,只需要将黑色区域和白色区域的颜色换一下就好了,简单而且高效。
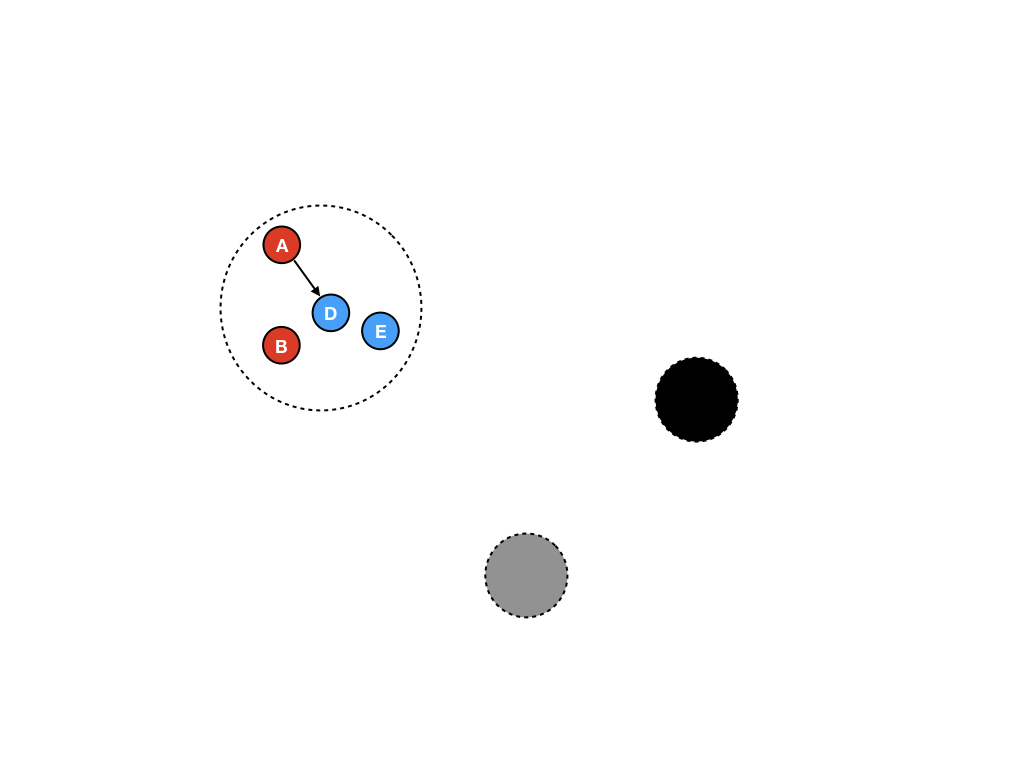
GC三色算法小结
上面就是三色标记清除算法的一些细节,在当前算法下仍旧有两个阶段需要 stop-the-world:一是进行root内存对象的栈扫描;二是标记阶段的终止暂停。令人激动的是,标记阶段的终止暂停将被去除。在实践中我们发现,用这种算法实现的GC暂停时间能够在超大堆空间回收的情况下达到<1ms的表现。
延迟 VS 吞吐
如果一个并行GC收集器在处理超大内存堆时能够达到极低的延迟,那么为什么还有人在用stop-the-world的GC收集器呢?难道Go的GC收集器还不够优秀吗?
这不是绝对的,因为低延迟是有开销的。最主要的开销就是,低延迟削减了吞吐量。并发需要额外的同步和赋值操作,而这些操作将会占用程序的处理逻辑的时间。而Haskell的GHC则针对吞吐量进行了优化,Go则专注于延迟,我们在考虑采用哪种语言的时候需要针对我们自己的需求进行选择,对于推送系统这种实时性要求比较高的系统,选择Go语言则是权衡之下得到的选择。
实际表现
目前而言,Go好像已经能够满足低延迟系统的要求了,但是在实际中的表现又怎么样呢?利用相同的benchmark测试逻辑实现进行比较:该基准测试将不断地向一个限定缓冲区大小的buffer中推送消息,旧的消息将会不断地过期并成为垃圾需要进行回收,这要求内存堆需要一直保持较大的状态,这很重要,因为在回收的阶段整个内存堆都需要进行扫描以确定是否有内存引用。这也是为什么GC的运行时间和存活的内存对象和指针数目成正比例关系的原因。
这是Go语言版本的基准测试代码,这里的buffer用数组实现:
package main
import (
"fmt"
"time"
)
const (
windowSize = 200000
msgCount = 1000000
)
type (
message []byte
buffer [windowSize]message
)
var worst time.Duration
func mkMessage(n int) message {
m := make(message, 1024)
for i := range m {
m[i] = byte(n)
}
return m
}
func pushMsg(b *buffer, highID int) {
start := time.Now()
m := mkMessage(highID)
(*b)[highID%windowSize] = m
elapsed := time.Since(start)
if elapsed > worst {
worst = elapsed
}
}
func main() {
var b buffer
for i := 0; i < msgCount; i++ {
pushMsg(&b, i)
}
fmt.Println("Worst push time: ", worst)
}
相同的逻辑,不同语言实现(Haskell/Ocaml/Racke
| Benchmark | Longest pause (ms) |
|---|---|
| OCaml 4.03.0 (map based) (manual timing) | 2.21 |
| Haskell/GHC 8.0.1 (map based) (rts timing) | 67.00 |
| Haskell/GHC 8.0.1 (array based) (rts timing) | 58.60 |
| Racket 6.6 experimental incremental GC (map based) (tuned) (rts timing) | 144.21 |
| Racket 6.6 experimental incremental GC (map based) (untuned) (rts timing) | 124.14 |
| Racket 6.6 (map based) (tuned) (rts timing) | 113.52 |
| Racket 6.6 (map based) (untuned) (rts timing) | 136.76 |
| Go 1.7.3 (array based) (manual timing) | 7.01 |
| Go 1.7.3 (map based) (manual timing) | 37.67 |
| Go HEAD (map based) (manual timing) | 7.81 |
| Java 1.8.0_102 (map based) (rts timing) | 161.55 |
| Java 1.8.0_102 G1 GC (map based) (rts timing) | 153.89 |
令人惊讶的是Java,表现得非常一般,而OCaml则非常之好,OCaml语言能够达到约3ms的GC暂停时间,这是因为OCaml采用的GC算法是incremental GC algorithm(而在实时系统中不采用OCaml的原因是该语言对多核的支持不好)。
正如表中显示的,Go的GC暂停时间大约在7ms左右,表现也好,已经完全能够满足我们的要求。
一些注意事项
- 进行基准测试往往需要多加小心,因为不同的运行时针对不同的测试用例都有不同程度的优化,所以表现往往也有差异。而我们需要针对自己的需求来编写测试用例,对于基准测试应该能够满足我们自己的产品需求。在上面的例子中可以看到,Go已经完全能够满足我们的产品需求。
- Map Vs. Array: 最初我们的基准测试是在map中进行插入和删除操作的,但是Go在对大型的map进行GC的时候存在Bug。因此在设计Go的基准测试的时候用可修改的Array作为Map的替代。Go map的Bug已经在1.8版本中得到了修复,但是并不是所有的基准测试都得到了修正,这也是我们需要正视的一些问题。但是不管怎么说,没有理由说GC时间将会因为使用map导致大幅度增长(除去bug和糟糕的实现之外)。
- manual timing Vs. rst timing :作为另一个注意事项,有些基准测试则在不同的计时系统下将会有所差异,因为有些语言不支持运行时时间统计,例如Go,而有些语言则支持。因此,我们应该在测试时候都把计时方式设置为manual timing。
- 最后一个需要注意的事项是测试用例的实现将会极大地影响基准测试的结果,如果map的插入删除实现方式比较糟糕,则将会对测试结果造成不利影响,这也是用array的另一个原因。
为什么Go的结果不能再好点?
尽管我们采用的map bugfixed版本或者是array版本的go实现能够达到~7ms的GC暂停表现,这已经很好了,但是根据Go官方发布的“1.5 Garbage Benchmark Latency”](https://talks.golang.org/2015/go-gc.pdf) , 在200MB的堆内存前提下,能够达到~1ms的GC暂停延时(经管GC暂停时间应该和指针引用数目有关而和堆所占用的容量无关但我们无法得到确切数据)。而Twitch团队也发布文章称在Go1.7中能够达到约1ms的GC延迟。
在联系go-nuts mail list之后得到的答案是,这些暂停实验可能是因为一些未修复的bug导致的。空闲的标记worker可能会对程序逻辑造成阻塞,为了确定这个问题,我采用了go tool trace,一个可视化工具对go的运行时行为进行了跟踪。
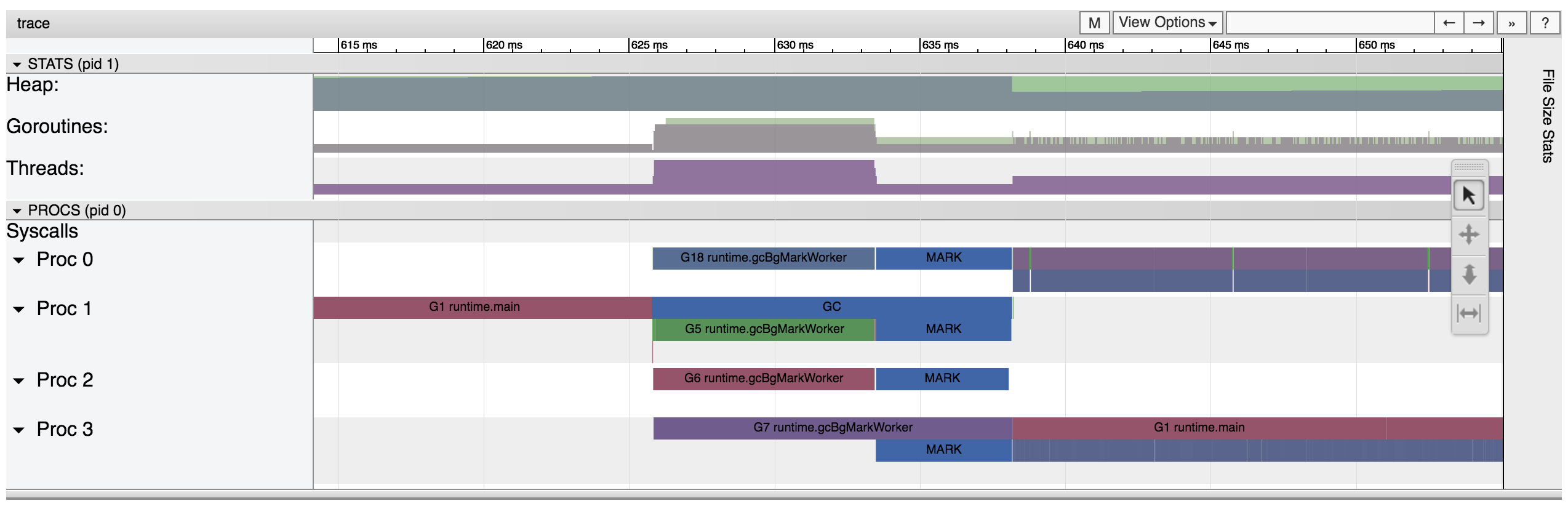
正如图所示,这里有近12ms的后台mark worker运行在所有的processor(CPU核?)中。这让我更加确信是上述的bug导致的该问题。
总结
这次调查的重点在于GC要么关注于低延迟,要么关注于高吞吐。当然这些也都取决于我们的程序是如何使用堆空间的(我们是否有很多内存对象?每个对象的生命周期是长还是短?)
理解底层的GC算法对该系统是否适用于你的测试用例是非常重要的。当然GC系统的实际实现也至关重要。你的基准测试程序的内存占用应该同你将要实现的真正程序类似,这样才能够在实践中检验GC系统对于你的程序而言是否高效。正如前文所说的,Go的GC系统并不完美,但是对于我们的系统而言是可以接受的。
尽管存在一些问题,但是Go的GC表现已经优于大部分同样拥有GC系统的语言了,Go的开发团队针对GC延迟进行了优化,并且还在继续。Go的GC确实是有可圈可点之处,无论是理论上还是实践中。