全链路追踪系统技术分析
前言
近期正好有机会接触到了一个全链路追踪的改造项目,正好给自己一个了解其他领域的机会,其实也是为我自己找到了一个能够挑战自己的机会,这是一个很重要的项目,也涉及非常复杂的系统和相关方。而长期以技术人员的思维考虑事情的我,觉得这是一个很好的挑战自我的机会,一方面能够了解一个相对陌生的领域的技术,另一方面,也能够拓宽自己的能力边界。
技术背景
整体的出发点其实是一个客户路程的追踪展示需求,需求说简单也挺简单的,即希望能够看到客户在使用APP的过程当中出现了哪些问题,导致这些问题的原因是什么。但其实这里面涉及到的内容是相对复杂的,这涉及到前端的数据埋点,以及后端的链路跟踪,这是一个端到端的全链路追踪系统。
其实全链路追踪这件事是有现成的解决方案的,在现代的微服务架构体系下,很多框架乃至解决方案都提供了非常完备的技术方案帮助追踪系统调用链路。但是不禁要问,究竟是什么时候起,需要全链路追踪系统了呢?
我们知道,在设计系统架构的时候,合适是一个非常重要的原则,简单的系统如单体系统乃至仅有一两个微服务的系统,我们在分析系统解决问题的时候,其实是相对快速方便的,不存在调用链路冗长复杂,系统依赖关系模糊的情况,只有在软件系统发展到一定规模,系统业务达到一定量级了,才需要大量的服务去支撑完整系统,这个过程恰恰为大型信息系统演变的过程。
Distributed Programming is the art of solving the same problem that you can solve on a single computer using multiple computers — Mikito Takada
所谓 “天下大事,合久必分”,软件系统往往也类似,达到一定规模,复杂度上升到一定程度,拆分是解决复杂性问题的优选方案,分布式系统横空出世,用来解决单机系统无法解决的问题。但是微服务架构带来的问题也很突出,系统很多,链路很长,服务器集群规模很大,出了问题往往没有办法快速定位原因。
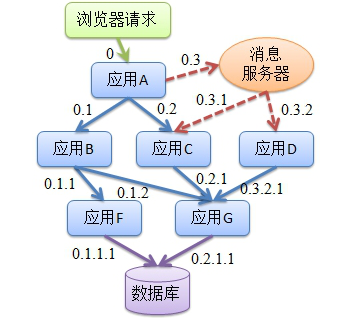
为了解决这个业务规模增长带来的软件系统规模增长引发的开发维护难度也快速增长的尖锐问题,链路追踪自然而然成为了解决问题的良方。
现有系统分析
分布式系统的链路追踪和故障定位已经成为系统规模增之后不得不解决的难题,困扰着开发者的还包括这些问题:
- 根因定位难:原来笔者在支付宝工作时,除了一个线上故障,往往要拉好几个团队的人一起看,因为很多服务都拆分给了很多团队负责,出了问题很难说清楚是哪个服务的问题,所以一堆人都要到线上看,没有有效的跟踪定位能力,效率必然低下。
- 容量评估难:就如木桶原则,整个系统的性能短板在哪里,所有流量的毕竟之地,以及大促的时候需要重点关注以及扩容的服务是哪个,需要做出这些判断没有一个有效的链路请求数据真的只能拍脑袋随便猜。
- 架构设计难:在进行系统分析和架构设计的时候,往往需要对上下游的依赖进行分析评估以确定影响,没有一个有效的链路追踪系统,只能如盲人摸象,有文档还好,老司机指点也行,如果没有,只能看代码自求多福。
- 性能优化难:同容量评估类似,链路数据能够帮助我们快速找到系统的性能瓶颈,一个用户请求响应慢,服务返回不及时,到底是哪个服务导致的一目了然,也不用推诿扯皮。
上面的都是问题,这也帮助我们澄清了全链路系统应该解决的需求,链路架构与服务浏览地图、耗时、异常数据的采集与展现都是需要解决的问题。
Google 的 Dapper
2010年Google发布了一篇名叫《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》的论文,被业界誉为分布式系统链路追踪的开山级文献。该文献详细叙述了Google 内部是如何实现一个低损耗、应用透明、大规模的监控追踪系统来为生产系统保驾护航的。在 Dapper 之前 Magpie系统已经针对性能调试、容量规划、系统调优和异常检测等方面提出了一些解决思路。而 X-Trace则提供了一个针对网络流量的追踪方案。Dapper 结合了两者的优势。本小节则重点分析 Dapper 中几个重要的设计。
调用树与跨度(Span)
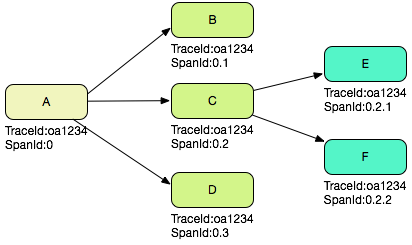
在一次调用过程当中,服务依赖关系可以是很复杂的,在Dapper中,举了如下图的例子:
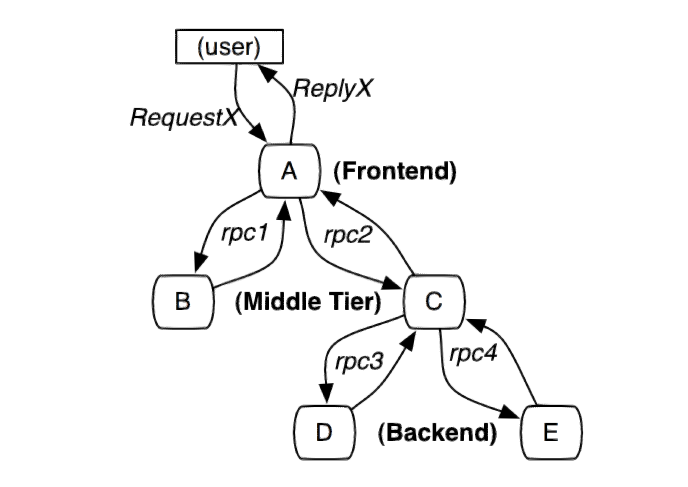 这个路径由用户的X请求发起,穿过一个简单的服务系统。用字母标识的节点代表分布式系统中的不同处理过程
这个路径由用户的X请求发起,穿过一个简单的服务系统。用字母标识的节点代表分布式系统中的不同处理过程
如上图所示,用户发起的请求,内部进行了4次RPC调用,而且并不仅仅由A系统发起,C系统也发起了两次调用,可以清晰地看出来,调用存在一定的树形关系。
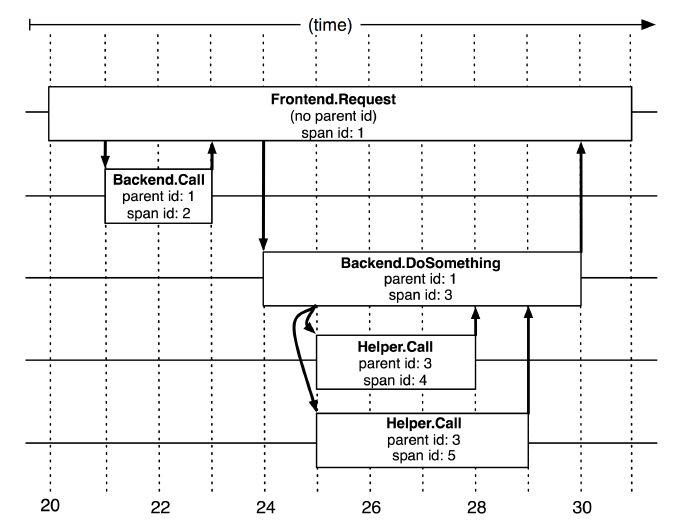 这张图能够更加清晰地标识调用之间的时序关系,为了串联一个完整的请求,自然而然地,我们会想到使用唯一的请求id用来标识一次用户请求,这也就是我们常听说的
这张图能够更加清晰地标识调用之间的时序关系,为了串联一个完整的请求,自然而然地,我们会想到使用唯一的请求id用来标识一次用户请求,这也就是我们常听说的 trace id 这个想法自然且正确,但随之而来的问题是,trace id 能够确定一组内部请求,但是无法表示树形的层级结构,因为信息量不够,构建一个树形结构需要引入新的信息,这就是跨度,也就是父调用和当前调用信息,我们称之为 parent span 和current span。
在跨度(span)信息中加上开始调用和结束调用时间,我们就能够迅速确定调用链的层级关系和性能信息,所以,一次调用需要一直携带的上下文信息包括:
|
|
也许 endTS可以用调用延时来替代,但这只是实现细节差异了。
植入点
上文提及,调用需要携带上下文信息,但是如何携带其实是一个非常复杂的问题,Dapper设计的过程当中需要达到应用透明的要求,也就意味着,不可以侵入系统,但是为了能够将追踪上下文信息贯穿全链路,上下文信息的透传是必须的。 为了不侵入业务,Dapper 针对一些少量的通用组件进行了改造,主要改造内容包括:
- 基于一个请求一个线程处理的前提,Dapper 把单次请求的上下文放在 ThreadLocal 中进行存储。追踪上下文包括 traceID和span ID,被设计为了轻量的格式便于快速序列化。
- 如果调用不是同步的,比如延迟调用的或是异步调用的,比如通过线程池或流程执行器调用,他们大多使用一个一个通用的控制流库来回调。Dapper 对通用控制流库进行了改造,确保所有异步回调可以存储这次跟踪的上下文,而当回调函数被触发时,该次跟踪的上下文会与适当的线程关联上,这样Dapper依旧可以使用 TraceID 和 SpanID 来辅助构建异步调用路径。
- 更为重要的是,进程间边界之间的透传,几乎所有的Google系统服务的进程间通信是建立在一个用C++和Java开发的RPC框架上。Dapper 修改该框架来让RPC调用能够携带追踪上下文信息,TraceID 和 SpanID 会从客户端发送到服务端。当然,这要求有统一的应用框架来完成这件事情。
Annotation (注解)
此注解非 Java 中的注解
有上面的基础,其实已经能够推导出追踪的链路细节了,但是也仅限于此,明显我们还需要一些额外的信息,比如缓存命中率啊,计算耗时,业务数据等。Dapper 提供了 Annotation 的能力,除了链路信息,也可以携带透传一些额外信息,如用户ID等,Annotation 可以是文本,也可以是键值对,这个设计也为后面的追踪系统提供了类似Tag或是Bagger的能力。
采样率
Dapper 设计的另一个目标就是低损耗,所以提供了一个采样采集的能力,如果请求量很大,而采集系统又很耗费性能,显然会把原有的服务拖垮。这样服务提供方也不愿意部署这个拉胯的追踪系统。因此Dapper设计了一个采样少部分流量的能力,而采样多少流量的比率就被称为采样率,这是一个非常好的设计,一方面降低了服务方的顾虑,另一方面也可以降低采集分析端的存储和分析压力,能够很好地控制损耗。
Dapper 的采集架构示意
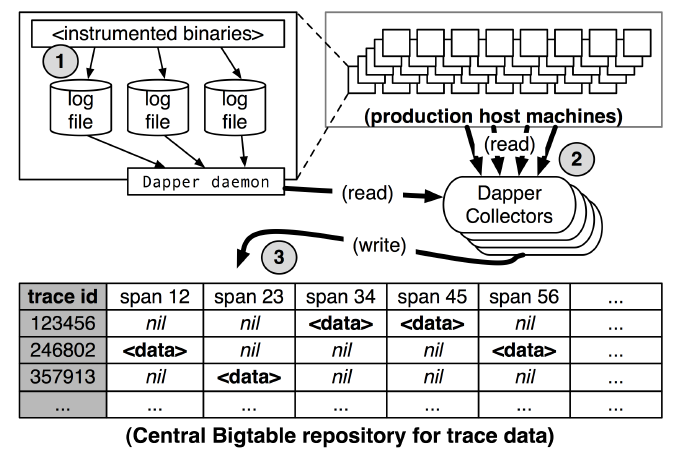 Dapper 跟踪记录和收集的过程分为三个阶段(参见上图)。
Dapper 跟踪记录和收集的过程分为三个阶段(参见上图)。
- 首先,应用系统将 span数据写入(1)本地日志文件中。
- 然后,Dapper的守护进程和收集组件把这些数据从生产环境的主机中拉出来(2)
- 最终写到(3)Dapper的Bigtable仓库中。
一次跟踪数据被设计成 Bigtable 中的一行,每一列相当于一个 span 。Bigtable 的支持稀疏表格布局正适合这种情况,因为每一次跟踪可以有任意多个 span。
- 这也就说明了类似的数据其实比较适合存在 HBase 这种数据库中
- 有关请求延时数据,建议参考原论文,本文觉得没有参考意义,就不放了。
Dapper 的一些实施细节
- Google 几乎在所有的生产服务器上都部署了 Dapper 的跟踪收集守护进程;
- 一些非RPC框架的系统如原生TCP Socket和SOAP RPC的库,是无法支持Dapper跟踪的,因此需要单独编码接入到Dapper中;
- 考虑到生产环境的安全,Dapper 默认是关闭的,可以通过开关打开;
- Annotation携带的额外数据是很有必要的,70%的Dapper span和90%的所有 Dapper Trace 都至少携带一个额外 Annotation 数据;
- 系统损耗包括两部分,一部分是生成追送和收集追踪数据带来的性能下降;另一部分是存储和分析追踪数据,第一部分会影响应用服务本身,第二部分则通过分布式系统降低了影响;
Dapper运行库中最重要的跟踪生成消耗在于创建和销毁span和annotation,并记录到本地磁盘供后续的收集。根span的创建和销毁需要损耗平均204纳秒的时间,而同样的操作在其他span上需要消耗176纳秒。时间上的差别主要在于需要在跟span上给这次跟踪分配一个全局唯一的ID。
Dapper 的API 设计
数据存储之后需要进行查询分析,Dapper为此设计了几个API (Dapper API, DAPI):
- 通过 TraceID 来访问:DAPI 可以通过他的全局唯一的 TraceID 读取任何一次请求跟踪信息;
- 批量访问:DAPI 可以利用 MapReduce 提供对上亿条 Dapper 跟踪数据的并行读取。用户重写一个虚拟函数,它接受一个 Dapper 的跟踪信息作为其唯一的参数,该框架将在用户指定的时间窗口中调用每一次收集到的跟踪信息;(在线 MR 是一种非常昂贵的设计)
- 索引访问:Dapper 的存储仓库支持一个符合通用调用模板的唯一索引。该索引根据通用请求跟踪特性(commonly-requested trace features)进行绘制来识别 Dapper 的跟踪信息。因为跟踪ID是根据伪随机的规则创建的,这是去访问跟某个服务或主机相关的跟踪数据最好的办法。 (设计特定的索引是非常有必要的,在实际系统应用当中,通过服务名称搜索是非常常见的)
Dapper 的UI设计
Dapper 论文介绍了几个典型的UI流程,如下图所示:
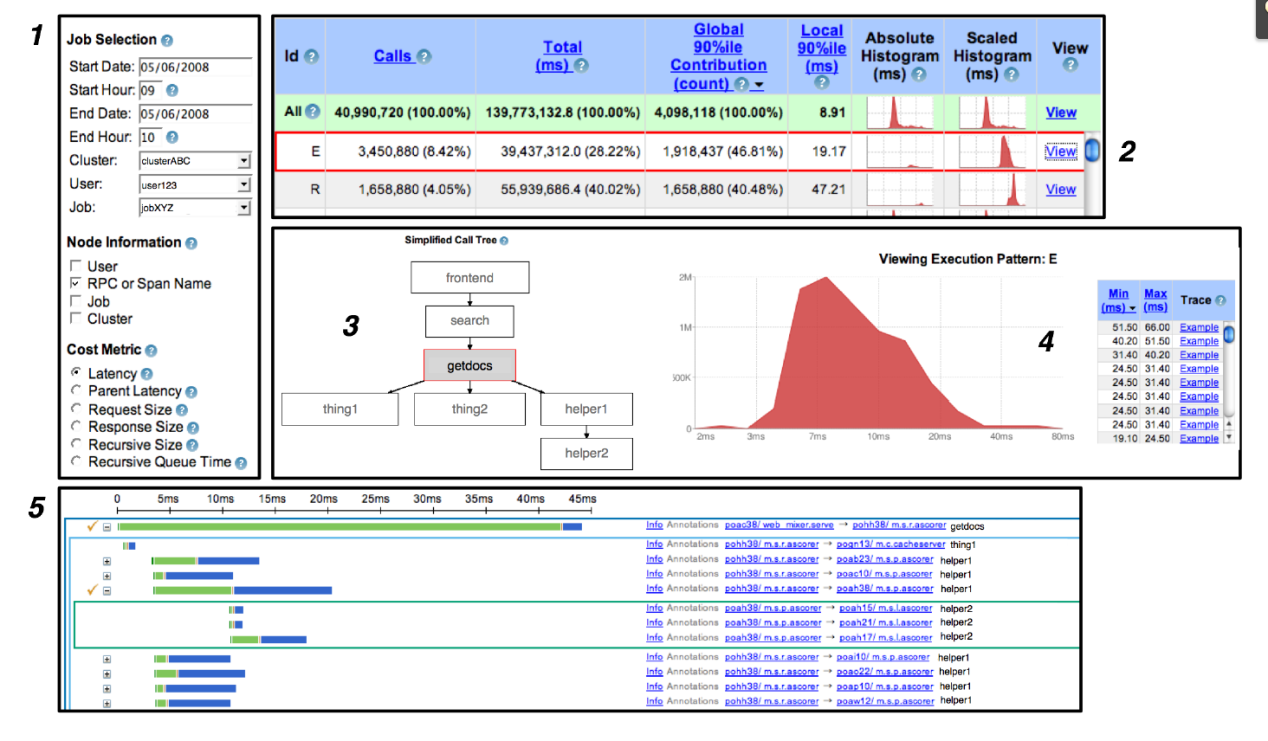
- 用户可以查询服务和响应时间,通过输入Trace的搜索条件完成,比如span的名称;同时用户也可以选择他们关心的一些成本度量(cost metric)如服务响应时间;
- 性能概要的表格,能够对应相关联的各项服务,用户可以将执行信息进行自由排序,或者选择一种直方图去展现更多的细节;
- 一旦某个单一的分布式执行跨度被选中后,用户能看到关于执行跨度的的图形化描述。被选中的服务被高亮展示在该图的中心;
- 在生成与步骤1中选中的成本度量(cost metric)维度相关的统计信息之后,Dapper的用户界面会提供了一个简单的直方图。在这个例子中,我们可以看到所选中部分的一个大致的分布式响应时间分布图。
- 用户需要检查某个跟踪的具体情况,Dapper 使用由一个全局时间轴(下方绿框处),并能够展开和折叠树形结构。分布式跟踪树的连续层用内嵌的不同颜色的矩形表示。每一个RPC的span被从时间上分解为一个服务器进程中的耗时(绿色部分)和在网络上的耗时(蓝色部分)。用户 Annotation 可选展示。
Dapper 总结
Dapper 提供了一个很好的追踪系统的实践参考,尽管其没有提供具体的数据结构设计和框架代码实现,但是它提出的跨度信息、采样率、Annotation等概念为后面的pinpoint、CAT、SkyWalking的实现都提供了重要的借鉴意义。在他们的设计过程当中,我发现在Google的十几年前的论文中就能够发现他们系统设计的先进性和架构基础设施的前瞻性,确实给我带来的相当震撼和启发。
Woonduk Kang 的 Pinpoint
Pinpoint 是一个 APM(应用程序性能管理)工具,用于用 Java/PHP 编写的大型分布式系统。受 Dapper 的启发,Pinpoint 提供了一种解决方案,通过跟踪分布式应用程序中的事务来帮助分析系统的整体结构以及其中的组件如何互连。
Pinpoint 能够解决的问题
如今的服务通常由许多不同的组件组成,它们相互之间进行通信以及对外部服务进行 API 调用。每笔交易的执行方式通常都被保留为黑匣子。 Pinpoint 跟踪这些组件之间的事务流,并提供清晰的视图来识别问题区域和潜在的瓶颈。
- 应用程序拓扑图
- 应用程序实时监控
- 单笔交易的代码级可见性
- 无代码侵入性
- 性能损耗极小(3%) 上述的能力似乎看上去比Dapper强上不少,事实上,在开源的APM系统当中,Pinpoint也算是佼佼者了。
Pinpoint的架构设计
Pinpoint的架构设计非常有借鉴意义,几乎是一个采集系统最简单的架构体系了,如下图所示:
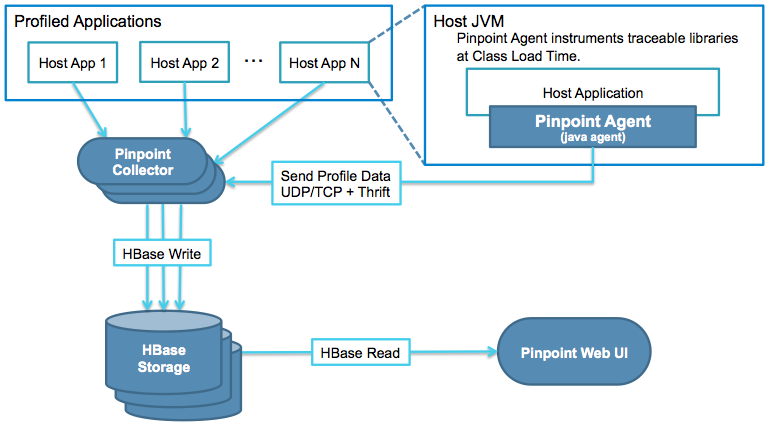 一个追踪系统包括如下几个部分:
一个追踪系统包括如下几个部分:
- 采集部分:也就是上图的 Agent和 Collector
- 存储部分:即上图的 HBase Storage
- 分析部分:集成在了 Pinpoint Web UI 中
- 展现部分: 主要是 Pinpoint Web UI
首先讲讲 Agent 部分,采用了 java agent 技术进行字节码增强,这个技术用来做APM其实非常合适,在之前的工作当中也接触到用来做应用流量复制(影子流量)的,原理并不复杂,javaagent 技术其实就是一个特殊的 jar 文件,利用 JVM 提供的 Instrumentation API 来更改加载到 JVM 中的字节码。技术细节将在后文介绍。
Pinpoint 的数据结构设计
pinpoint是基于Dapper进行设计的,其数据结构也类似,主要包括:
- Span: RPC(远程过程调用)跟踪的基本单元;它表示当 RPC 到达并包含跟踪数据时处理的工作。为了确保代码级别的可见性,Span 将标记为 SpanEvent 的子项作为数据结构。每个 Span 包含一个 TraceId。
- Trace: 一个 Span 的集合;它由相关的 RPC(跨度)组成。同一跟踪中的 Span 共享相同的 TransactionId。 Trace 通过 SpanIds 和 ParentSpanIds 排序为层次树结构。
- TraceId:由 TransactionId、SpanId 和 ParentSpanId 组成的键的集合。 TransactionId 表示消息ID,SpanId 和ParentSpanId 都代表RPC 的父子关系。
- TransactionId (TxId):从单个事务跨分布式系统发送/接收的消息的 ID;它在整个服务器组中必须是全局唯一的。
- SpanId:接收RPC消息时处理的作业ID;它是在 RPC 到达节点时生成的。
- ParentSpanId (pSpanId):生成 RPC 的父 span 的 SpanId。如果节点是事务的起点,则不会有父跨度 - 对于这些情况,我们使用值 -1 来表示跨度是事务的根跨度。
与 Dapper 的差异是,Pinpoint 中的 TransactionId 等于 Dapper 中的 TraceId, 但是笔者人为 Pinpoint 的术语设计多少有点混乱,Trace 是Span的集合, TraceId则不代表这个集合,而是 TxId, SpanId和ParentSpanId的集合,这个极容易混淆。
其实在Pinpoint中真正在传递的只有 TxId, SpanId和ParentSpanId:
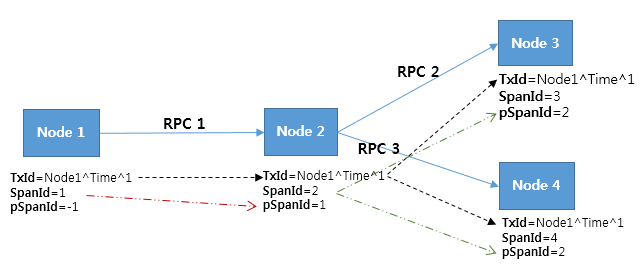
Pinpoint 可以使用 TransactionId 找到关联的 n 个 Span,并可以使用 SpanId 和 ParentSpanId 将它们排序为分层树形结构。
SpanId 和 ParentSpanId 是 64 位长整数。由于数字是任意生成的,因此可能会出现冲突,但考虑到从 -9223372036854775808 到 9223372036854775807 的值范围,这不太可能发生。
TransactionId 由 AgentIds、JVM(Java 虚拟机)启动时间和 SequenceNumbers 组成。
- AgentId:JVM启动时用户创建的ID;它在安装了 Pinpoint 的整个服务器组中必须是全局唯一的。使其唯一的最简单方法是使用主机名 ($HOSTNAME),因为主机名通常不重复;
- JVM 启动时间:需要保证从零开始的唯一序列号。此值用于防止用户错误创建重复的 AgentId 时发生 ID 冲突;
- SequenceNumber:Pinpoint Agent下发的ID,从零开始依次递增的数字;针对每条请求消息生成;
Dapper 和 Twitter 的分布式系统跟踪平台 Zipkin 生成随机 TraceId(Pinpoint 中的 TransactionId)并将冲突情况视为正常情况。但在 Pinpoint 中尽可能避免这种冲突。为此,Pinpoint 采用了ID生成空间大,携带数据长但冲突概率低的方式解决。
所有的系统在设计过程当中均不采用中心化分发ID的方式,一方面可以避免中心化分发系统宕机所带来的服务不可用风险,另一方面也分担了性能开销。
Pinpoint的字节码增强技术
Twitter 的 Zipkin 使用修改后的基础库及其容器 (Finagle) 提供分布式事务跟踪功能。但显然,它需要修改代码。Pinpoint采用了javaagent技术,实现了无需修改代码即可追踪的能力,并达成了代码级别的可见性并自动处理标签信息。
| Item | 优势 | 劣势 |
|---|---|---|
| 手工埋点 | API简单,可以最小化bug风险 | 需要开发人员修改代码,追踪能力弱 |
| 自动增强 | 无需修改代码,可以采集更加丰富的数据 | 相对代码埋点开销高;需要更加专业的人员能够开发相对核心底层中间件追踪系统;代码bug风险更大,影响更广,因此需要专家进行开发 |
字节码增强难度更大,风险更高,当然带来的收益也就更多。开发agent需要大量的研发资源,需要非常专业的java专家进行开发,但是带来的好处就是,应用服务端则基本不需要改造了。如果服务数量足够多,开发足够复杂,应该将成本转移到agent的开发。
基于Javaagent技术的代码追踪能力还有一些隐藏的优势:
- 无需担心API设计的缺陷,如果采用代码埋点方式,一个API的修改需要修改大量服务,这基本上是不能承受的,因此一开始就要把API设计好;
- 方便地开关,Javaagent技术能够帮助我们快速地启用或者禁用追踪,而代码埋点则需要应用系统进行配置,无法很好地控制;
Javaagent 启用的 JVM参数命令,如果出问题了,可以去掉这些命令
|
|
Pinpoint 的一些技术细节
使用二进制格式(thrift) Pinpoint可以使用二进制格式 (Thrift) 来提高编码和传输速度,提高网络使用效率(使用和调试比较困难)。
使用可变长度编码 常见的编码方式是整型4或8字节,这种称为定长编码,空间利用效率多少会低一些,而Pinpoint 通过 Thrift 的 Compact Protocol 将数据编码为可变长度,优化存储传输空间。
通过常量表来表示特定API 或 SQL 直接将API请求信息和SQL信息发送至后端会导致信息过载,通过建立一个常量到API或是SQL的映射可以大大减小网络传输和存储的压力,这个常量映射存储在HBase中。
追踪采样 Pinpoint在针对大流量系统中可以只采样 1~5%的流量,降低分析压力。
使用异步数据传输降低应用线程影响
- Pinpoint 采用异步的方式传输数据,即使传输失败也不会影响业务线程;
- Pinpoint 使用UDP的方式传输数据,降低网络不稳定对系统带来的影响,同时提供了API,用户可以自己调整传输方式;
Pinpoint 的UI 界面
-
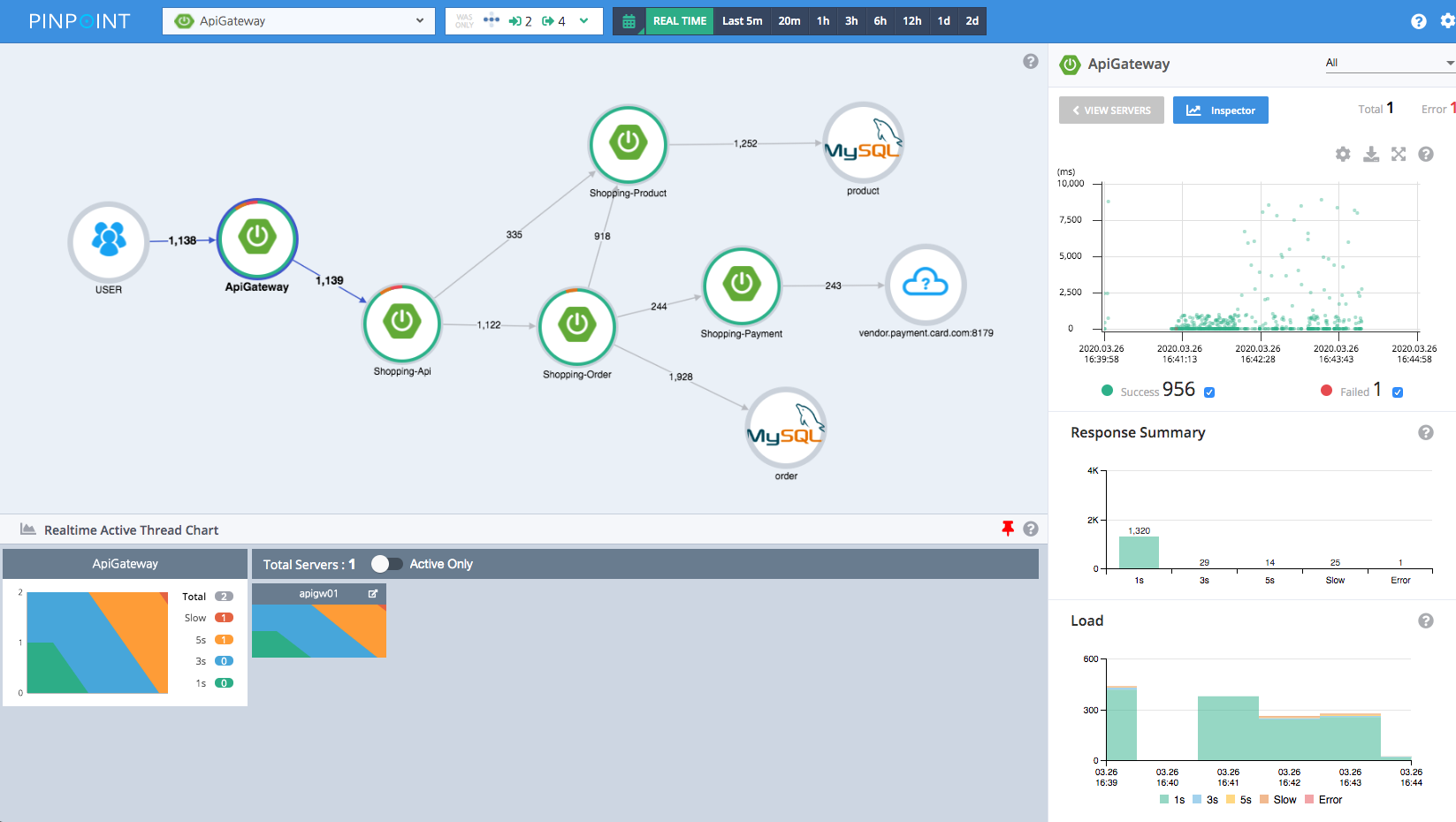
ServerMap - 可以展示当前服务的拓扑图,点击一个节点,可以展示这个节点的细节,比如当前的状态和处理的交易数量
-
Realtime Active Thread Chart - 实施跟踪当前应用内部的线程数量。
-
Request/Response Scatter Chart -当前的请求和响应的散点图,能够发现潜在问题;当然点击交易信息通过“挖掘”能力查看。
-
CallStack - 取得代码级别的可视化能力,在分布式环境下可以快速找到当前请求的瓶颈在哪,就和本地调用一样
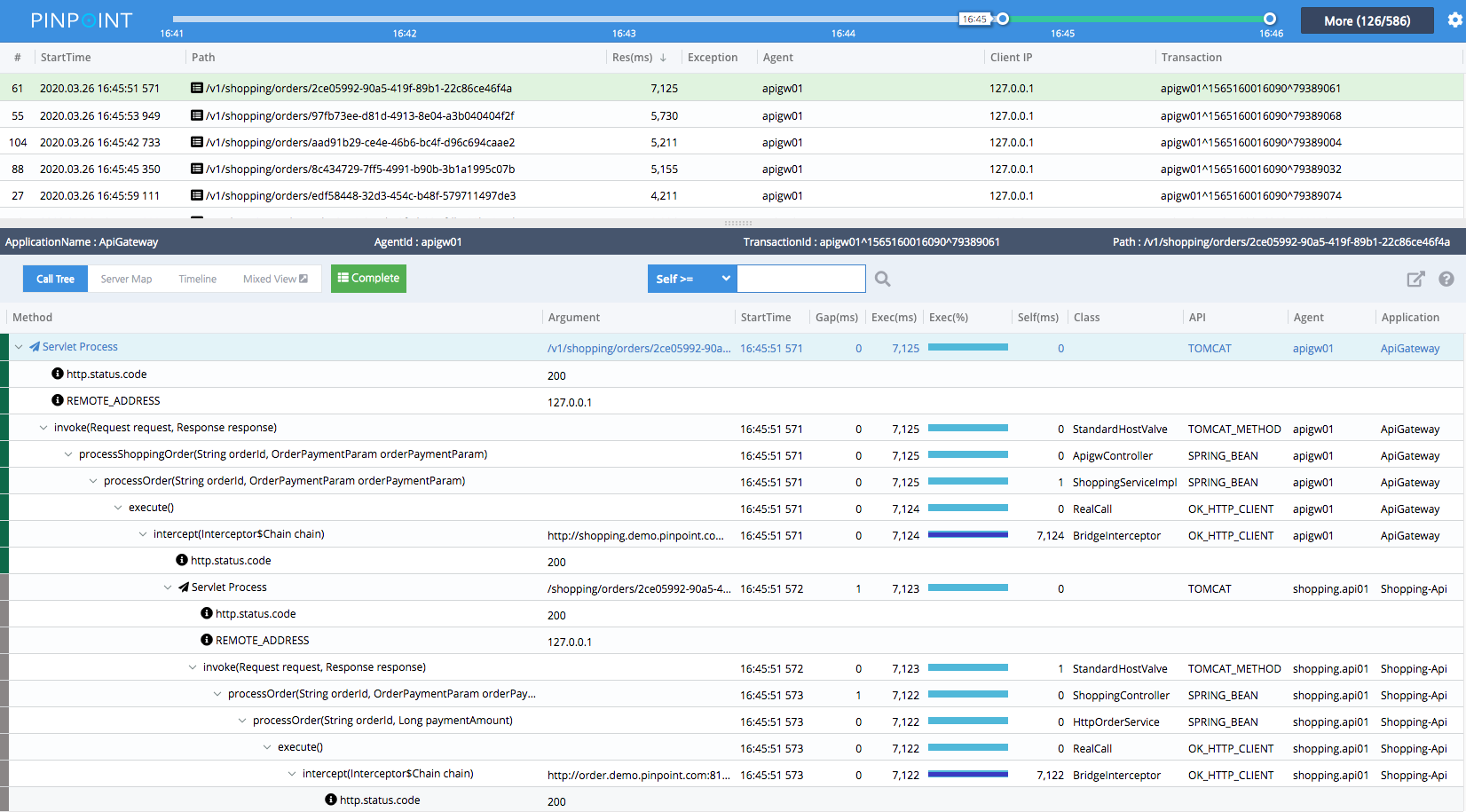
-
Inspector - 更多的额外信息,比如CPU,内存,GC时间以及TPS,JVM参数等
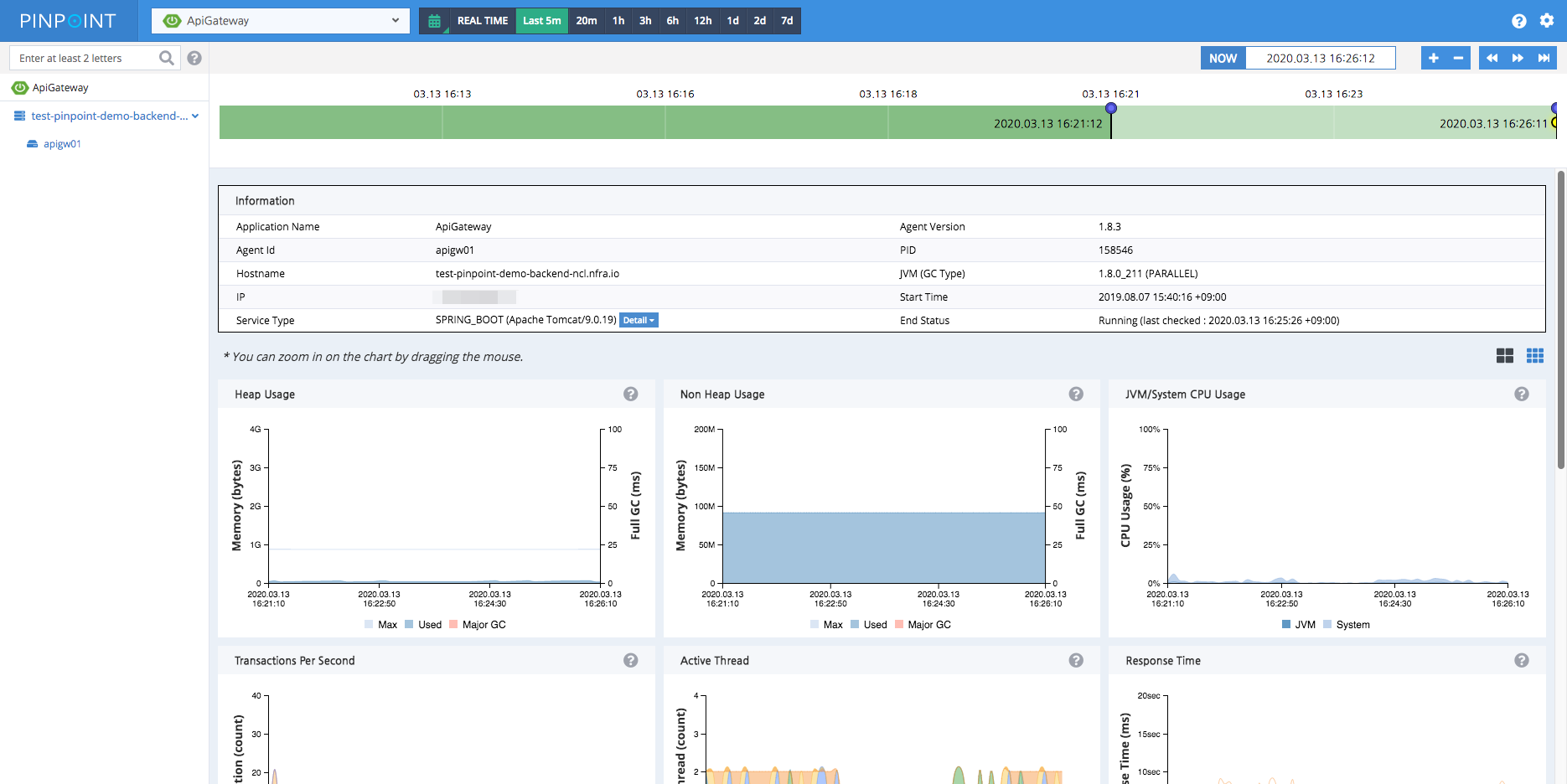
Pinpoint 总结
Pinoint做Java的监控其实很不错了,功能都有,并且能够完成所有的关键能力,可视化做的也可以。但是也仅限于Java了。
Twitter 的 zipkin
相比于 Pinpoint Twitter的追踪系统 Zipkin 则简单一些。Zipkin 能够收集微服务架构中的延迟问题所需的时间数据。
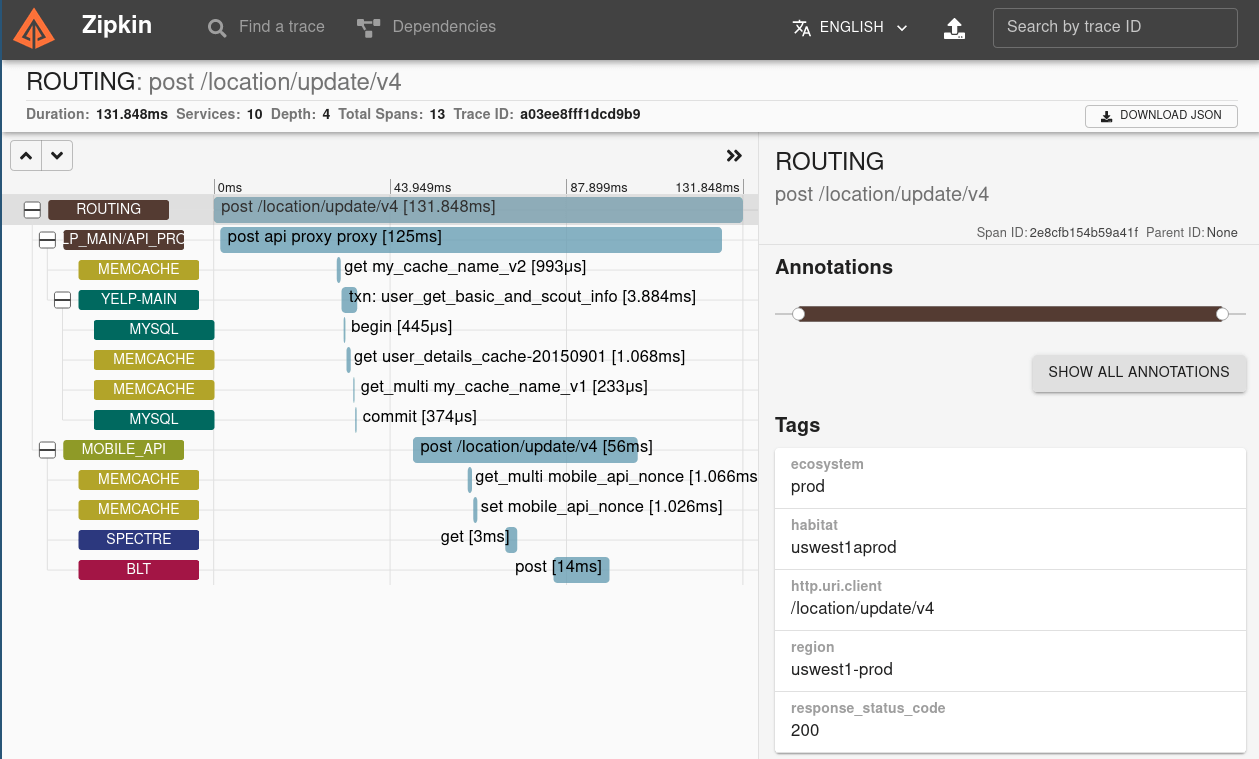
Zipkin可以通过TraceId进行搜索,当然如果没有的话,可以通过 service, operation name tags等信息进行搜索,Zipkin能够提供一个带跨度层级的延迟信息。
Zipkin也提供了一个能够查询链路拓扑的界面,虽然有一些简陋:
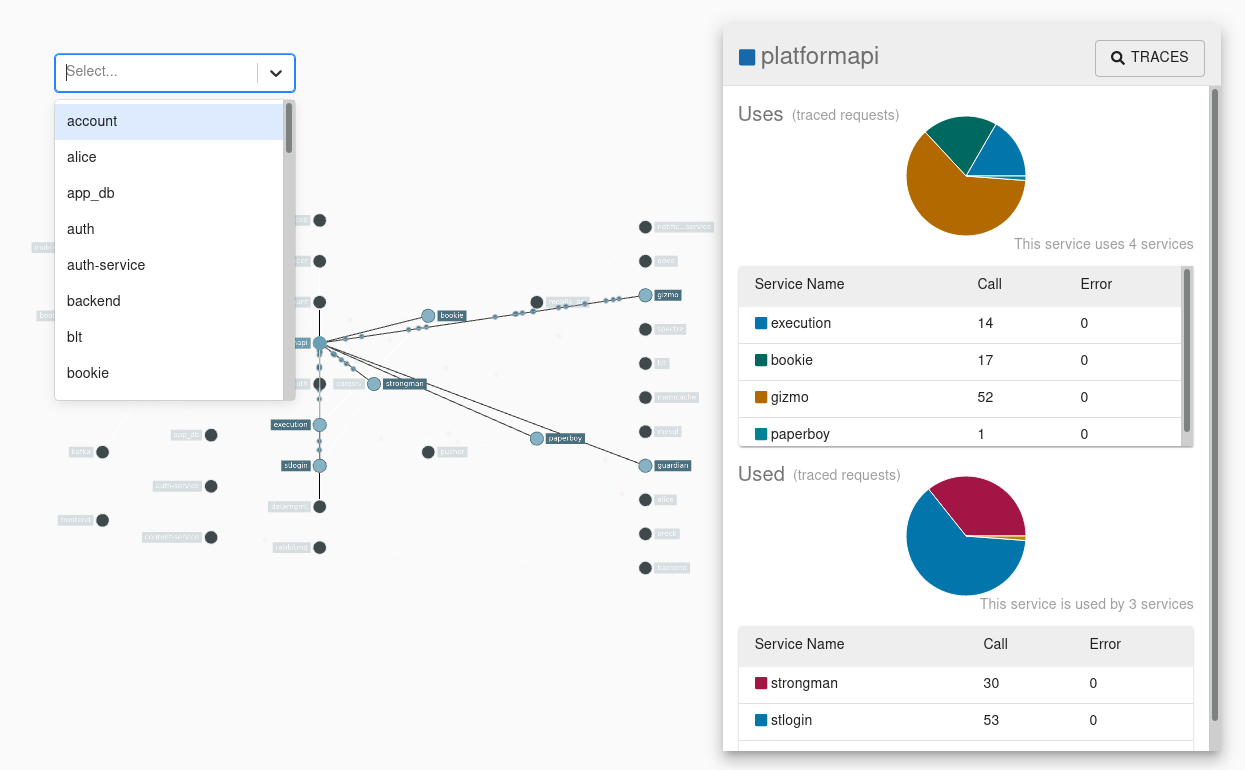 Zipkin 也通过agent技术获取数据,利用HTTP协议或是Kafka等队列技术发送给后端,最后存储到 Apache Cassandra或Elasticsearch中。
Zipkin 也通过agent技术获取数据,利用HTTP协议或是Kafka等队列技术发送给后端,最后存储到 Apache Cassandra或Elasticsearch中。
Zipkin的架构
Zipkin的架构非常简单,主要设计和Dapper也大同小异,所以也没有什么好介绍的。 Zipkin 中有四个组件:
- collector 采集器:最终数据到达 Zipkin 收集器守护程序后,将对其进行验证、存储和索引,以供查找。
- storage 存储:原生支持 Cassandra,还支持 ElasticSearch 和 MySQL。
- search 搜索(分析):查询程序提供了一个简单的 JSON API 供 WebUI 来检索跟踪数据
- webUI 展示:Web UI 提供了一种基于服务、时间和tag检索跟踪数据的方法。注意:UI 中无身份验证
Zipkin 的 agent 库采用Http协议,Kafka或 Scribe 协议将 span 数据发送至采集器。
Zipkin 的数据模型
Zipkin的数据模型由json定义,不清楚是如何处理大规模数据的,其模型定义如下所示:
|
|
核心数据也是 traceId, spanId, parentSpanId,这些Id都是随机生成的:
当传入的请求没有附加跟踪信息时,会生成一个随机的 trace ID 和 span ID。spanID 可以作为 trace ID 的低 64 位重复使用,但也可以完全不同;
如果请求已经附加了跟踪信息,则服务应使用该信息,因为服务器接收和服务器发送事件与客户端发送和客户端接收事件属于同一跨度。
如果服务调用下游服务,则会创建一个新跨度作为前一个跨度的子级。它由相同的trace id,一个新的span id标识,并且父id被设置为前一个span的span id。新的 span id 应该是 64 个随机位。
注意如果服务使多个下游调用,则必须重复此过程。这是每个后续跨度都有相同的跟踪ID和父ID,而是一个新的和不同的跨度ID。
一些zipkin的技术细节
- 时间是用毫秒的
- span.Timestamp 和 duration 只能由启动跨度的服务设置,(原因没看明白)
dianpin 的 CAT
大众点评开源的 CAT(Central Application Tracking),是基于 Java 开发的分布式实时监控系统。CAT在基础存储、高性能通信、大规模在线访问、服务治理、实时监控、容器化及集群智能调度等领域提供业界领先的、统一的解决方案。 CAT 支持四种消息类型的监控:
- Transaction 适合记录跨越系统边界的程序访问行为,比如远程调用,数据库调用,也适合执行时间较长的业务逻辑监控,Transaction用来记录一段代码的执行时间和次数
- Event 用来记录一件事发生的次数,比如记录系统异常,它和transaction相比缺少了时间的统计,开销比transaction要小
- Heartbeat 表示程序内定期产生的统计信息, 如CPU利用率, 内存利用率, 连接池状态, 系统负载等
- Metric 用于记录业务指标、指标可能包含对一个指标记录次数、记录平均值、记录总和,业务指标最低统计粒度为1分钟
CAT的架构设计
CAT主要分为三个模块,cat-client,cat-consumer,cat-home
- cat-client 嵌入SDK, 提供给业务以及中间层埋点的底层sdk。
- cat-consumer 采集器, 用于实时分析从客户端提供的数据。
- cat-home 分析查询,作为用户提供给用户的展示的控制端。
CAT使用 HDFS 进行存储。
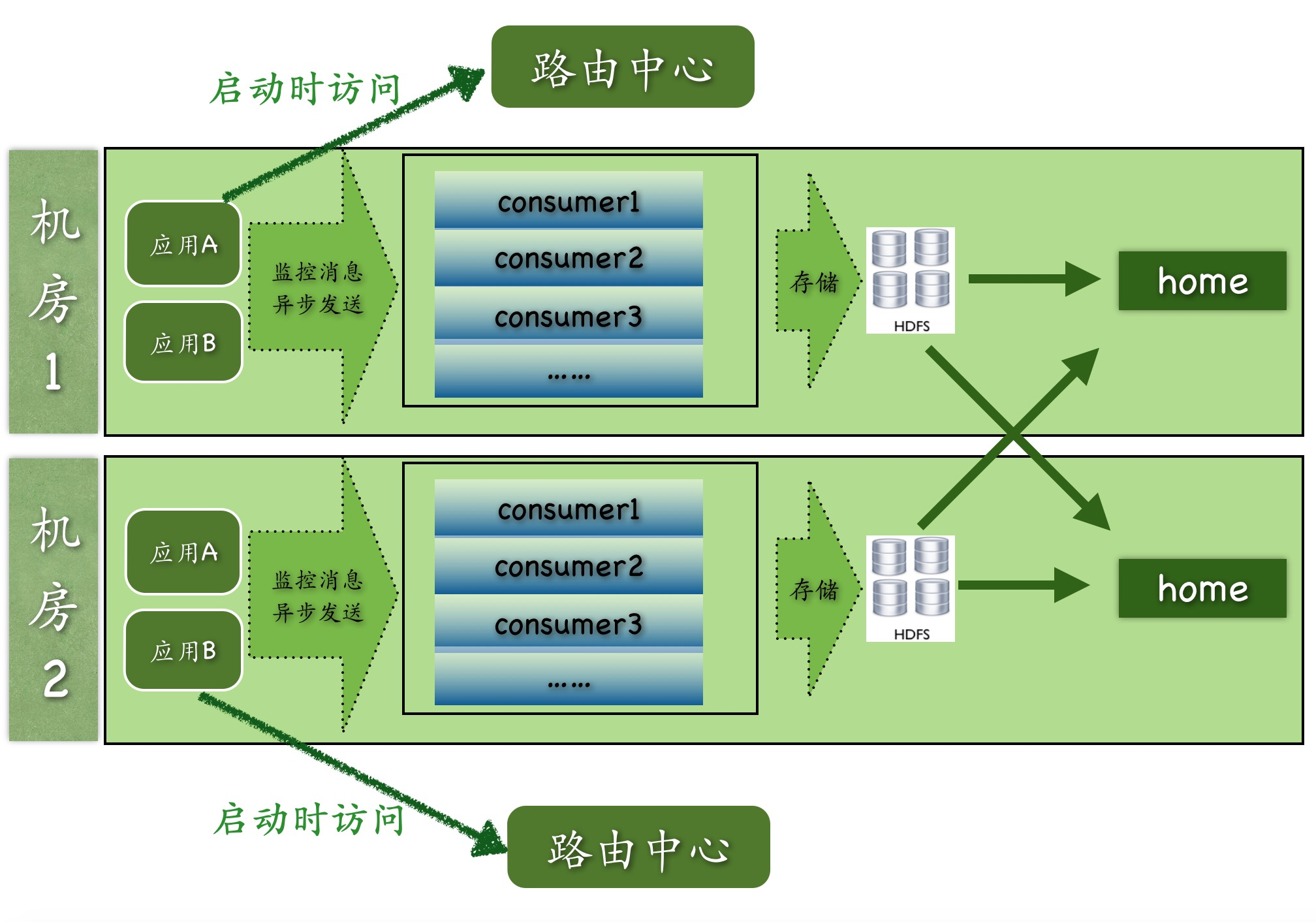 上图是CAT目前多机房的整体结构图:
上图是CAT目前多机房的整体结构图:
- 路由中心是根据应用所在机房信息来决定客户端上报的CAT服务端地址
- 每个机房内部都有的独立的原始信息存储集群HDFS
- cat-home可以部署在一个机房也可以部署在多个机房,在做报表展示的时候,cat-home会从cat-consumer中进行跨机房的调用,将所有的数据合并展示给用户
- 实际过程中,cat-consumer、cat-home以及路由中心都是部署在一起,每个服务端节点都可以充当任何一个角色
CAT 是侵入式的 用户需要集成 CAT client进行代码的采集,这个过程是需要嵌入SDK的,和上面讨论的几个系统都有些差异。
CAT采用私有协议
- CAT序列化协议是自定义序列化协议,自定义序列化协议相比通用序列化协议要高效很多(文档原文)。
CAT是直接上报的
并不是通过日志输出异步上报的
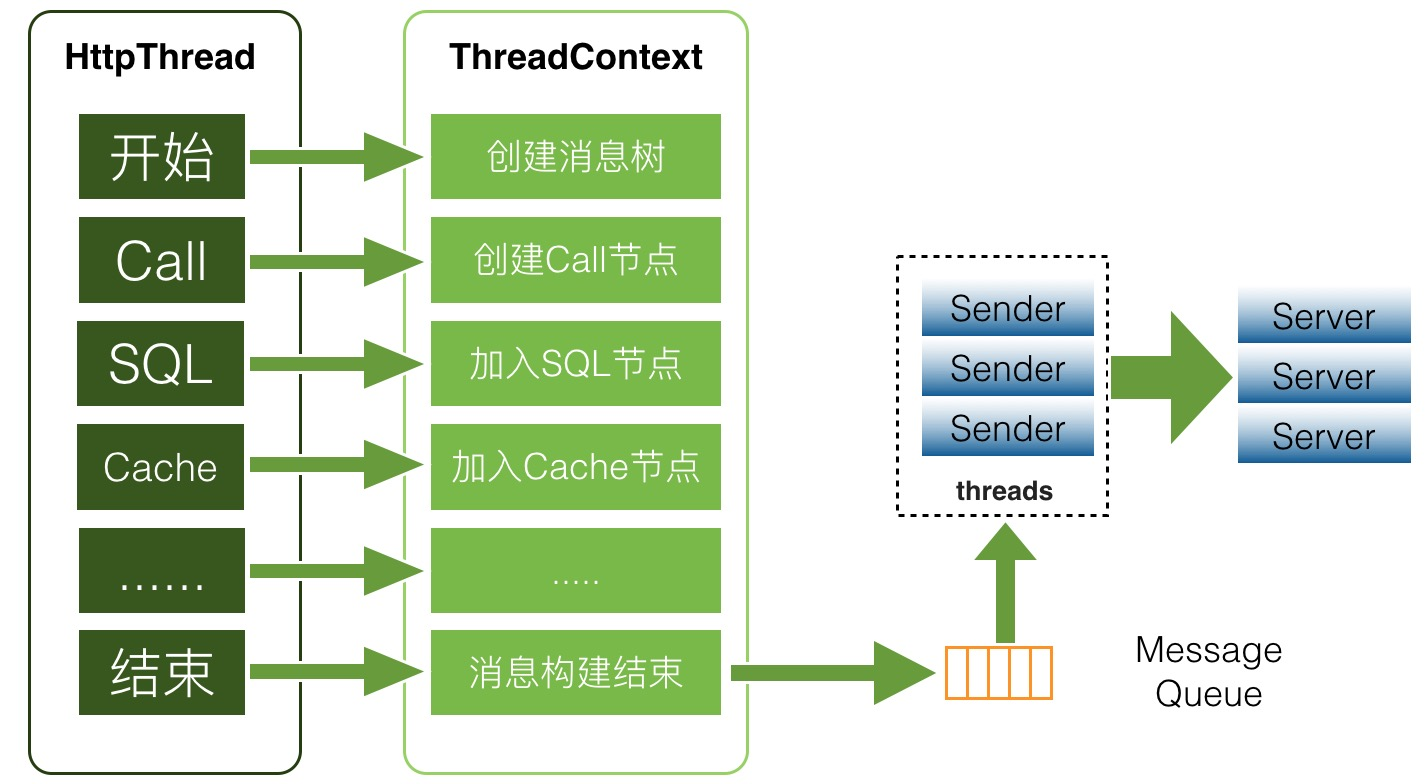 上图是CAT的客户端上报逻辑,取得数据后,放到内存队列并通过特定的线程发送至服务端。
上图是CAT的客户端上报逻辑,取得数据后,放到内存队列并通过特定的线程发送至服务端。
CAT 的服务端做分析再转储
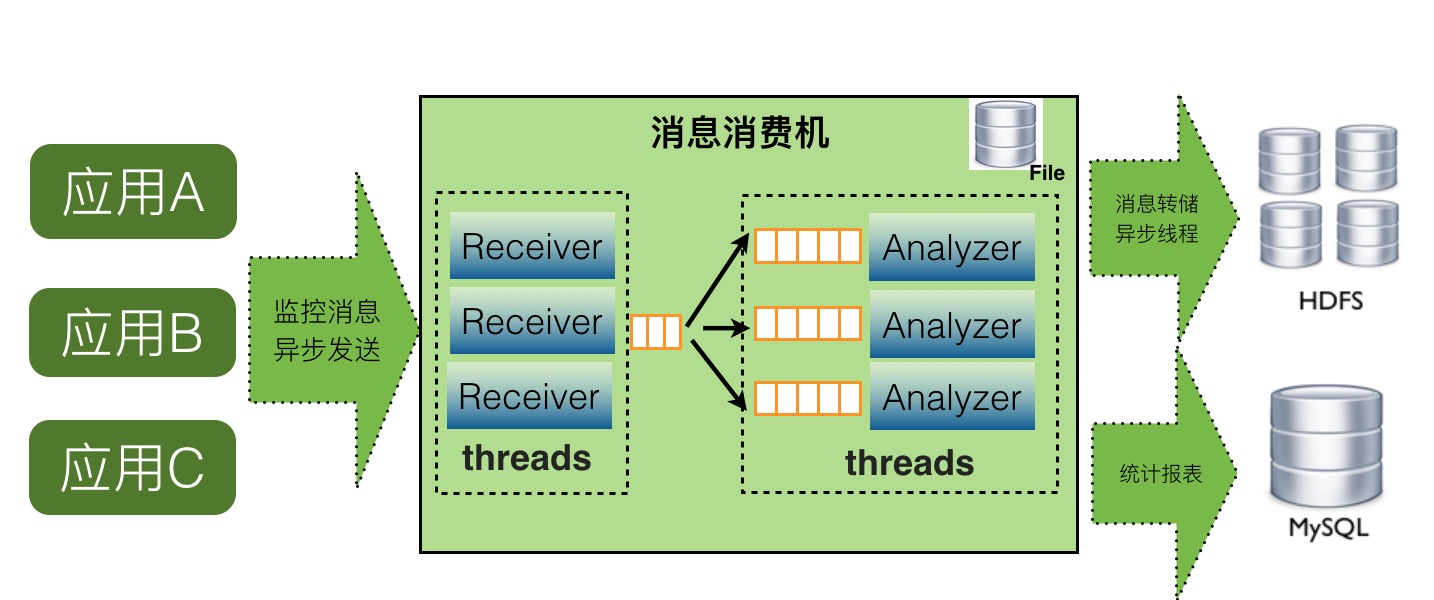 如上图,CAT服务端在整个实时处理中,基本上实现了全异步化处理。
如上图,CAT服务端在整个实时处理中,基本上实现了全异步化处理。
- 消息接收是基于Netty的NIO实现
- 消息接收到服务端就存放内存队列,然后程序开启一个线程会消费这个消息做消息分发
- 每个消息都会有一批线程并发消费各自队列的数据,以做到消息处理的隔离
- 消息存储是先存入本地磁盘,然后异步上传到hdfs文件,这也避免了强依赖hdfs
CAT的服务端直接进行了实时分析,主要采用内存分析,但是分析模型就是比较固定了:计数、计时和关系处理三种,基本上能够满足需求。
CAT 能够在服务端做实时处理,主要包括如下几个特性:
- 去中心化,数据分区处理
- 基于日志只读特性,以一个小时为时间窗口,实时报表基于内存建模和分析,历史报表通过聚合完成
- 基于内存队列,全面异步化,单线程化,无锁设计
- 全局消息ID,数据本地化生产,集中式存储
- 组件化、服务化理念
CAT 的存储设计
CAT 的数据结构没有与上面的系统一样,几乎是自定义了一套,可以看出来由一些差异,文档中也没有非常明显的地方体现这部分,可以看下图:
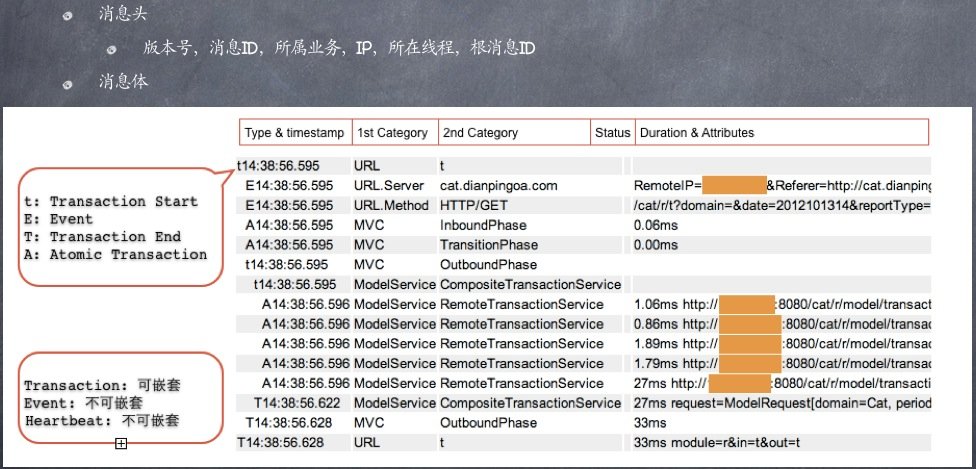 可以看到CAT协议的消息头中包括消息ID,根消息ID, 目前尚不清楚其实如何进行span关联的,内部重新定义了一个Transaction结构,说了可以嵌套,嵌套方式也很难在图上看出来。
可以看到CAT协议的消息头中包括消息ID,根消息ID, 目前尚不清楚其实如何进行span关联的,内部重新定义了一个Transaction结构,说了可以嵌套,嵌套方式也很难在图上看出来。
CAT的MessageID格式由四段组成,以ShopWeb-0a010680-375030-2为例:
- 第一段是应用名shop-web
- 第二段是当前这台机器的ip的16进制格式,01010680表示10.1.6.108
- 第三段的375030,是系统当前时间除以小时得到的整点数
- 第四段的2,是表示当前这个客户端在当前小时的顺序递增号
CAT针对消息日志也进行了压缩存储,目前看实时计算之后还需要把算出来的数据压缩存储至磁盘: 整体存储结构如下图
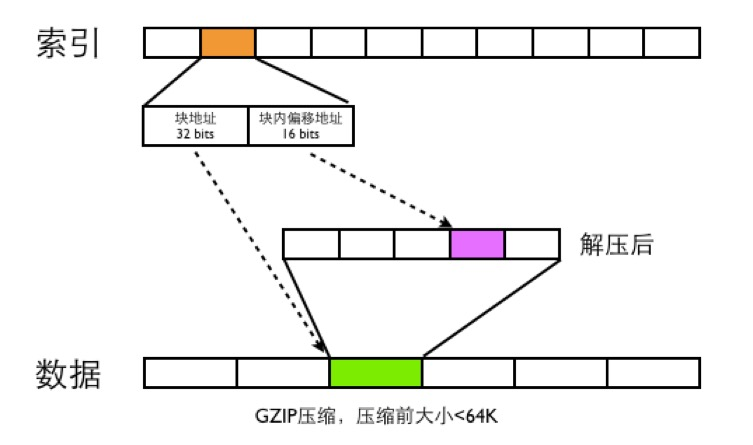
CAT数据文件分为两种,一类是index文件,一类是Data文件
- data文件是分段GZIP压缩,每个分段大小小于64K,这样可以用16bits可以表示一个最大分段地址
- 一个MessageId都用需要48bits的空间大小来存索引,索引根据MessageId的第四段来确定索引的位置,比如消息MessageId为ShopWeb-0a010680-375030-2,这条消息ID对应的索引位置为2*48bits的位置
- 48bits前面32bits存数据文件的块偏移地址,后面16bits存数据文件解压之后的块内地址偏移
- CAT读取消息的时候,首先根据MessageId的前面三段确定唯一的索引文件,在根据MessageId第四段确定此MessageId索引位置,根据索引文件的48bits读取数据文件的内容,然后将数据文件进行GZIP解压,在根据块内偏移地址读取出真正的消息内容。
笔者认为,CAT的存储模型限制了其分析能力,特别是二次的在线离线分析都受限了。
CAT总结
CAT 的报表能力是比较强的,但是从通信协议、存储模型、采集方式上看,都与市面上的成熟系统有较大差异,采用该系统容易与其绑死,扩展性也受限,如果是需要小成本轻量级的分析能力的话可以选用。
Apache 的 SkyWalking
最后再看看国人主导的 SkyWalking,单从界面上看,SkyWalking 已经秒杀上述一众系统了。
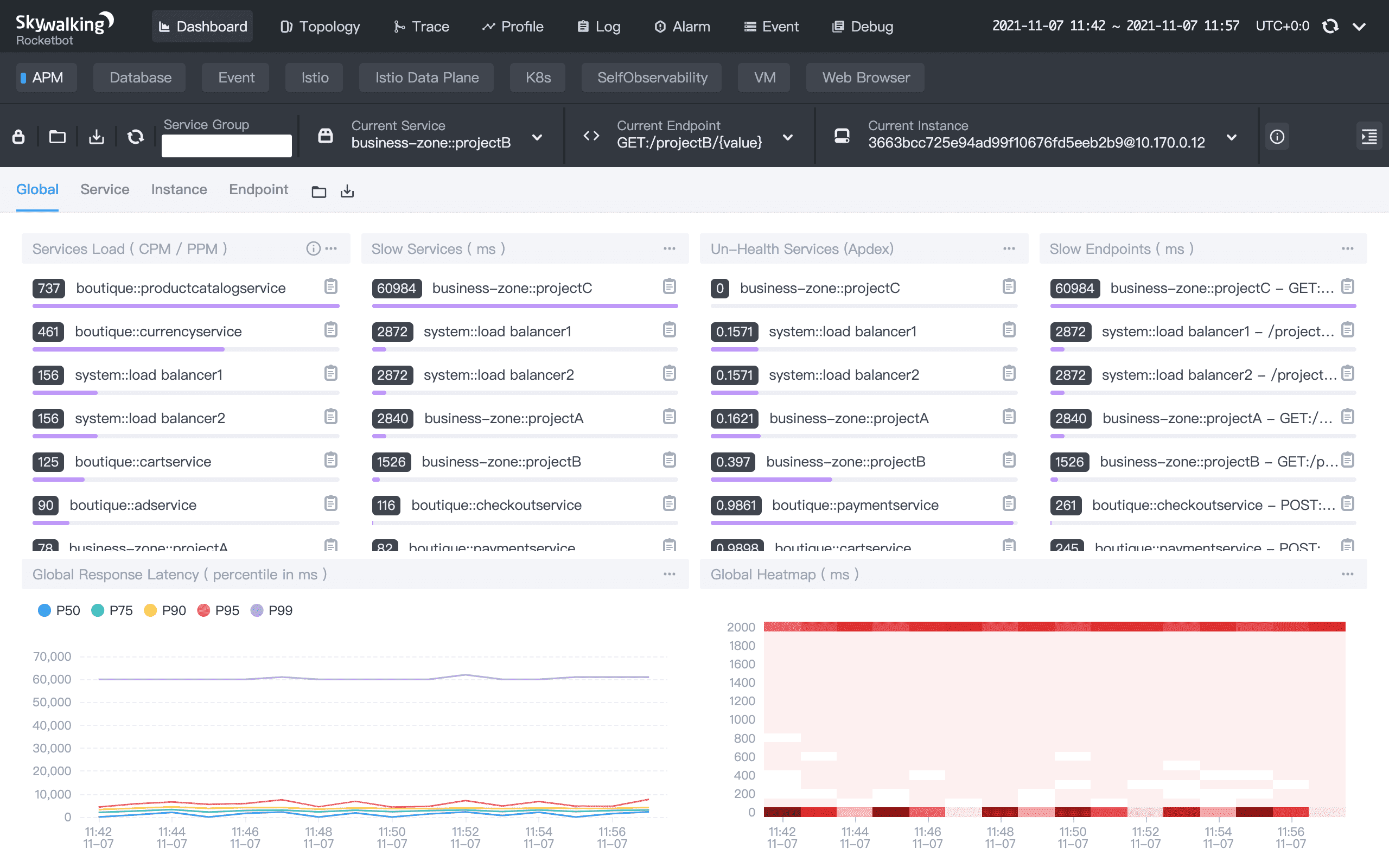
SkyWalking 的scope就大很多,定位为大而全的APM系统,希望能够采集链路、日志以及指标信息,并进行统一的分析和展示。
Skywalking 架构
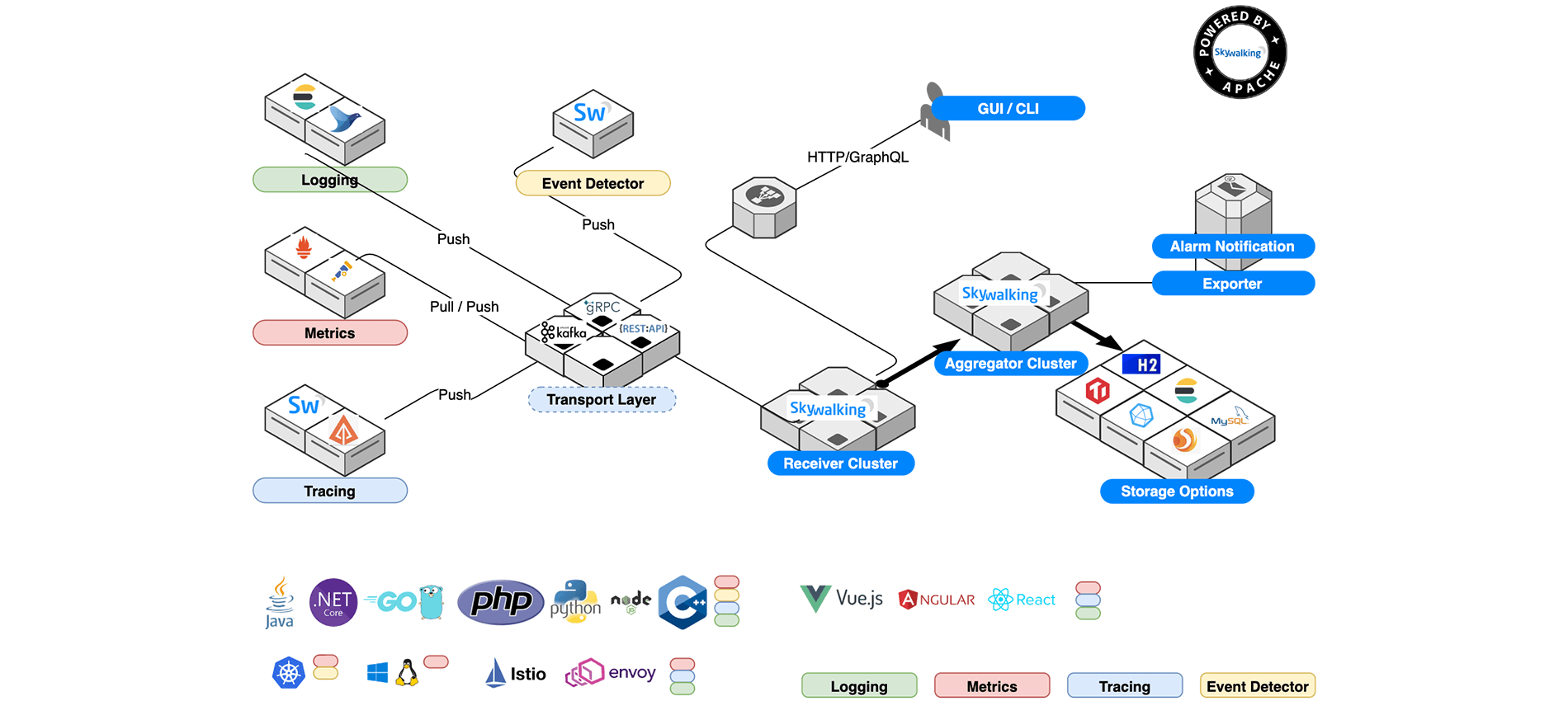
SkyWalking包括四个组件:探针, 平台后端,存储,UI
探针: 收集数据并重新重新格式化满足 Skywalking 要求(不同的探针支持不同的数据来源);
平台后端: 支持数据聚合,分析和流传输过程涵盖tracing,指标和日志;
存储: 通过开放/可插拔接口储存Skywalking数据。现有 Elasticsearch,H2,MySQL,TIDB,或是自行实现相关存储接口;
UI: 是一种高度可定制的基于Web的界面,允许Skywalking最终用户可视化和管理Skywalking数据;
Skywalking 则架构设计上更为现代,充分利用了开源社区的优势,整合了多种能力,如自动探针、手动SDK、以及服务网格 istio等。
skywalking的数据模型
- tracing, Skywalking 原生数据格式,支持 Zipkin V1 和 V2,包括 Jaeger。
- metrics,Skywalking与Service Mesh平台(例如Istio,Envoy和LinkerD)集成,以将可观察性构建到数据平面或控制平面中。此外,Skywalking本机代理可以在metrics模式中运行,这大大提高了性能。
- logging, 包括从磁盘或网络收集的日志,本机代理可以自动将跟踪上下文与日志绑定,或使用 Skywalking 绑定跟踪并记录文本内容。
其中 tracing 数据采用 Cross Process Propagation Headers Protocol和Cross Process Correlation Headers Protocol进行传输,这些数据通常在 HTTP/MQ/HTTP2的头中进行透传。
而 SkyWalking Trace Data Protocol V3 则是Agent/SDK传输给平台后端的协议,虽然协议名称这么多花里胡哨,但是最终发送给平台后端的数据使用grpc定义的:
|
|
在 SkyWalking 中,TraceSegment 是一个介于 Trace 与 Span 之间的概念,它是一条 Trace 的一段,可以包含多个 Span。在微服务架构中,一个请求基本都会涉及跨进程(以及跨线程)的操作,例如, RPC 调用、通过 MQ 异步执行、HTTP 请求远端资源等,处理一个请求就需要涉及到多个服务的多个线程。TraceSegment 记录了一个请求在一个线程中的执行流程(即 Trace 信息)。将该请求关联的 TraceSegment 串联起来,就能得到该请求对应的完整 Trace。
笔者人为, 这个Segment的设计定义不够清晰,没有办法明确划分边界,对上够不着trace对下又细不到span,这个设计的合理性还是存在疑问的。
日志记录和传输格式则通过SkyWalking Log Data Protocol定义(协议格式太多往往系统过于复杂)。
支持多种后端存储 目前分析支持多种存储后端,包括H2, ElasticSearch, MySQL, TiDB等
SkyWalking 总结
SW的设计是相对复杂的,生态也比较成熟,支持多种存储后端,也支持多种采集器方式,尤其是在 agent的支持方面,支持多语言、多方式,这点还是非常强大的,在开放标准兼容性方面,主动适配了Zipkin的协议,也为后续的扩展打好了基础。
在 javaagent 方面,目前分析主要是支持系统层面的能力,框架和调用层面的支持并没有详细说,分析下来应该是有待提高的。
监控的精细程度, Pinpoint 就略胜一筹了,能够做到代码级别的监控,而UI界面则SkyWalking就更加强大了,应该说是各有千秋,可以按照各自需求选用。
追踪系统标准
分布式系统追踪与监控出来有一段时间了,因此社区也已经自发地形成一些标准,这些标准包括OpenTracing、 OpenCensus 和 OpenTelemetry,这些标准都旨在构建更有效的方式来监控分布式系统。OpenCensus 是一个 Google 开源社区项目,其中 OpenTracing 是云原生计算基金会项目。OpenTelemetry 则是OpenCensus和OpenTracing的集大成者。
OpenTracing
“OpenTracing 用于跟踪的标准化 API,并提供了一种规范,开发人员可以使用该规范来检测服务或库以进行分布式跟踪。OpenTracing 还为开发人员提供了一种收集指标的方法,尽管它不是开箱即用的实现。”
所以,OpenTracing 是标准定义,不一定包括实现。
Open Census
“OpenCensus 是一组特定于语言的库,用于检测应用程序、收集统计数据(指标)并将数据导出到支持的后端。”
所以 OpenCensus 是一组实现,但是没有平台无关的标准定义。
OpenTelemetry
上述两个系统其实致力于解决同一个问题,而且各具优势,因此它们及时结合是很自然的。而且,OpenTelemetry 则接替了他们。
“OpenTelemetry 使强大的便携式遥测成为云原生软件的内置功能。提供一组 API、库、代理和收集器服务,以从您的应用程序中捕获分布式跟踪和指标。”
简单来说:OpenCensus + OpenTracing = OpenTelemetry
一些技术细节
聊聊SOFA Tracer
SOFATracer 是蚂蚁金服开发的基于 OpenTracing 规范 的分布式链路跟踪系统,其核心理念就是通过一个全局的 TraceId 将分布在各个服务节点上的同一次请求串联起来。通过统一的 TraceId 将调用链路中的各种网络调用情况以日志的方式记录下来同时也提供远程汇报到 Zipkin 进行展示的能力,以此达到透视化网络调用的目的(来自官网)。
之所以特意提及SOFA Tracer 是因为,这个系统其实设计的还算优雅(另一个原因是本人自己用过),经历过大规模的工程实践中,几个理念可以拿出来分析一下。
异步落地磁盘的日志打印能力 首先SOFATracer采用了打印日志的方式,不进行网络上报,我认为这是有好处的,首先不会增加网络实时通信的压力,在大促的时候可以减少对整体系统的影响。其次是持久化效果好,及时采集服务宕机,重启之后依旧能够采集到遗失的数据。
SLF4J的兼容性 事实上直接采用了SLF4J的能力,在大集团整体采用类似日志框架的前提下(这个不难统一)依赖冲突的情况将会大大缩减,集成成本大大降低。
遵循 Open Tracing 规范 遵循标准规范的好处就是,可以直接使用 zipkin 的UI进行展示(当然内部采用了更加高级的UI),在实际的工程当中,故障其实是通过两个系统完成的,trace定位服务,日志检索ELK定位错误。我们其实要有这样的认知,在服务量级足够大之后,存储和分析的压力都非常大,依赖于追踪系统完成根因分析的成本相对还是比较高的,这个时候人力成本是否应该纳入考虑?
SOFA Tracer 的接入方式相对轻量 尽管也是采用SDK接入的方式,由于框架比较统一,只需要引入Maven插件即可完成接入,不需要太侵入业务,这个成本相对还是低廉的,这其实是在 agent 探针和完全SDK代码埋点之间的一个平衡,我觉得这个设计还是非常绝妙的。
TraceId 和 SpanId 生成规则 SOFA Tracer 将TraceId和SpanID的生成规则讲得明明白白:
TraceId 一般由接收请求经过的第一个服务器产生,产生规则是: 服务器 IP + 产生 ID 时候的时间 + 自增序列 + 当前进程号 ,比如:
|
|
而SpanId则通过如下方式生成:
SpanId 目前的生成的规则参考了阿里的鹰眼组件。
应该说,上述的设计是优雅的,足够用,又不冗余,用29字节标识traceID,后续的spanID又足够简洁,符合标准,又不显冗余。
Javaagent 技术原理
java agent 的旁路增强原理,利用JVMTI对Java代码进行增强。
JVMTI (JVM Tool Interface)是Java虚拟机对外提供的Native编程接口,通过JVMTI,外部进程可以获取到运行时JVM的诸多信息,比如线程、GC等。Agent是一个运行在目标JVM的特定程序,它的职责是负责从目标JVM中获取数据,然后将数据传递给外部进程。加载Agent的时机可以是目标JVM启动之时,也可以是在目标JVM运行时进行加载,而在目标JVM运行时进行Agent加载具备动态性,对于时机未知的Debug场景来说非常实用。
我们使用Pinpoint的配图进行说明,如下图所示:
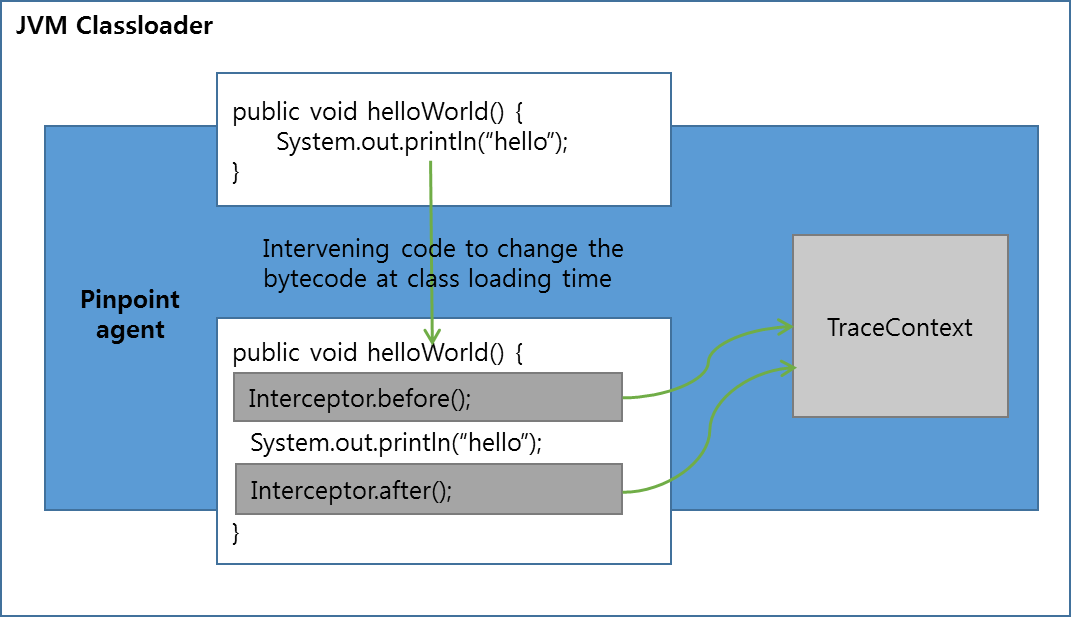
在用户类进行加载时,将会被 Pinpoint 的agent拦截到,并根据Pinpoint的agent内置的拦截器代码规则,针对特定的代码进行前后AOP增强,然后将追踪信息放入到追踪上下文中。 在 Pinpoint 中,API 拦截部分和数据记录部分是分开的。拦截器被注入到我们想要跟踪的方法中,并调用 before() 和 after() 方法来处理数据记录。通过字节码检测,Pinpoint Agent 可以仅从必要的方法记录数据,从而使分析数据的大小变得紧凑。
但是问题来了,用户写的代码已经被编译成字节码了,那么Pinpoint又如何完成拦截呢?这就涉及字节码动态修改了,其实原理和cglib的代理原理类似,但是是通过javaagent这种方式实现的,通过在启动的时候添加-ajavaagent参数完成增强,而字节码修改能力比较常见的库就有 byte-buddy等。
字节码检测技术必须处理 Java 字节码,往往会增加开发风险,同时降低效率。此外,对开发人员的要求也非常高,需要对拦截的代码点位非常熟悉,对不同的框架也非常了解,否则开发agent是非常有风险的一件事情。
分析总结
其实这篇文章讲的非常仔细,也基本覆盖了目前主流的系统,目前开源的系统都各有优缺点,需要根据实际情况进行分析取舍,如果希望能够有较为详细的信息供分析,可以考虑pinpoint,如果希望有比较好的UI, 对系统比较小的影响,可以考虑SkyWalking;如果希望使用一个相对轻量级的追踪系统,Zipkin也是可以考虑的。
本文对现有的追踪系统进行了分析,也初步介绍了一些分布式链路追踪系统的标准,希望能够给大家在分析设计过程当中提供参考。
参考文献
- Dapper, a Large-Scale Distributed Systems Tracing Infrastructure
- Magpie: online modelling and performance-aware systems
- X-Trace: A Pervasive Network Tracing Framework
- Pinpoint: Problem determination in large, dynamic, Internet service
- Dapper — Google’s Secret Weapon
- Pinpoint documentation
- pinpoint-techdetail
- zipkin documentation
- CAT wiki
- CAT model
- SkyWalking 的核心概念
- 全链路监控(一):方案概述与比较
- SOFA Tracer TraceId 和 SpanId 生成规则
- Guide to Java Instrumentation
- Java 动态调试技术原理及实践