Go 线程调度器
在Go1.1版本中,加入了由Dmitry Vyukov贡献的新的调度器。新的调度器能够动态地调整Go程序的并发性能,而且表现非常出色。因此我想写篇文章介绍一下这个调度器。
这篇博客里面大多数东西都已经被包含在了原始设计文档中了,这个文档的内容相当详实,但是过于技术化了。
虽然有关新调度器所有东西都在那个设计文档中,但这篇博客有图片配图了,所以比设计文档清晰易懂多了。
Go运行时为什么需要调度器?
在我们开始研究新调度器之前,我们首先需要理解为什么需要调度器。既然操作系统已经能够为我们调度线程了,我们为什么又创造了一个用户实现的调度器?
POSIX的线程API是对现有Unix进程模型在逻辑上的一个强大大的扩展,使得线程得到了很多类似进程的控制能力。比如,线程有它自己的信号码,线程能够被赋予CPU affinity功能(就是指定线程只能在某个CPU上运行),线程能被添加到cgroups中,线程所占用的的资源也能够查询。这些额外特性大大增加了Go 程序在创建goroutine 时所需要的开销,是在线程多达100000的时候尤其明显。
另外一个问题是,操作系统无法针对Go的设计模型给出很好的调度决策。比如,当运行一次垃圾收集的时候,Go的垃圾收集器要求所有线程都被暂停,并且要求内存要处于一致状态(consistent state)。这就要求所有等待所有正在运行的线程到同时达到一个一致点,而我们事先知道在这个一致点内存是一致的。
当很多被调度的线程分散在随机点(random point)上时,你不得不等待他们中的大多数到达一致状态才能进行垃圾回收。而Go调度器却能够只在内存一致的时候进行调度,这就意味着我们只需要等待在一个CPU核心中的活跃线程达到一致即可。
来看看里面的各个角色(Our Cast of Characters)
目前有三个常见的线程模型。一个是N:1的,即多个用户空间线程运行在一个OS线程上。这个模型可以很快的进行上下文切换,但是不能利用多核系统(multi-core systems)的优势。另一个模型是1:1的,即可执行程序的一个线程匹配一个OS线程。这个模型能够利用机器上的所有核心的优势,但是上下文切换非常慢,因为它需要进行系统内核调用。
Go试图通过M:N的调度器去获取这两种模型的全部优势。它在任意数目的OS线程上调用任意数目的goroutines。你可以快速进行上下文切换,并且还能利用你系统上所有的核心的优势。这个模型主要的缺点是它增加了调度器的复杂性。
为了完成调度任务,Go调度器使用了三个实体:

三角形表示OS线程,它是由OS管理的可执行程序的一个线程,而且工作起来特别像你的标准POSIX线程。在运行时代码里,它被成为M,即机器(machine)。
圆形表示一个goroutine。它包括栈、指令指针以及对于调度goroutines很重要的其它信息,比如阻塞它的任何channel。在运行时代码里,它被称为G。
矩形表示调度上下文。你可以把它看作是一个在单线程上进行线程调度的自定义版本。它是让我们从N:1调度器转到M:N调度器的重要部分。在运行时代码里,它被叫做P,即处理器(processor)。这部分将会进行较为详细的介绍。
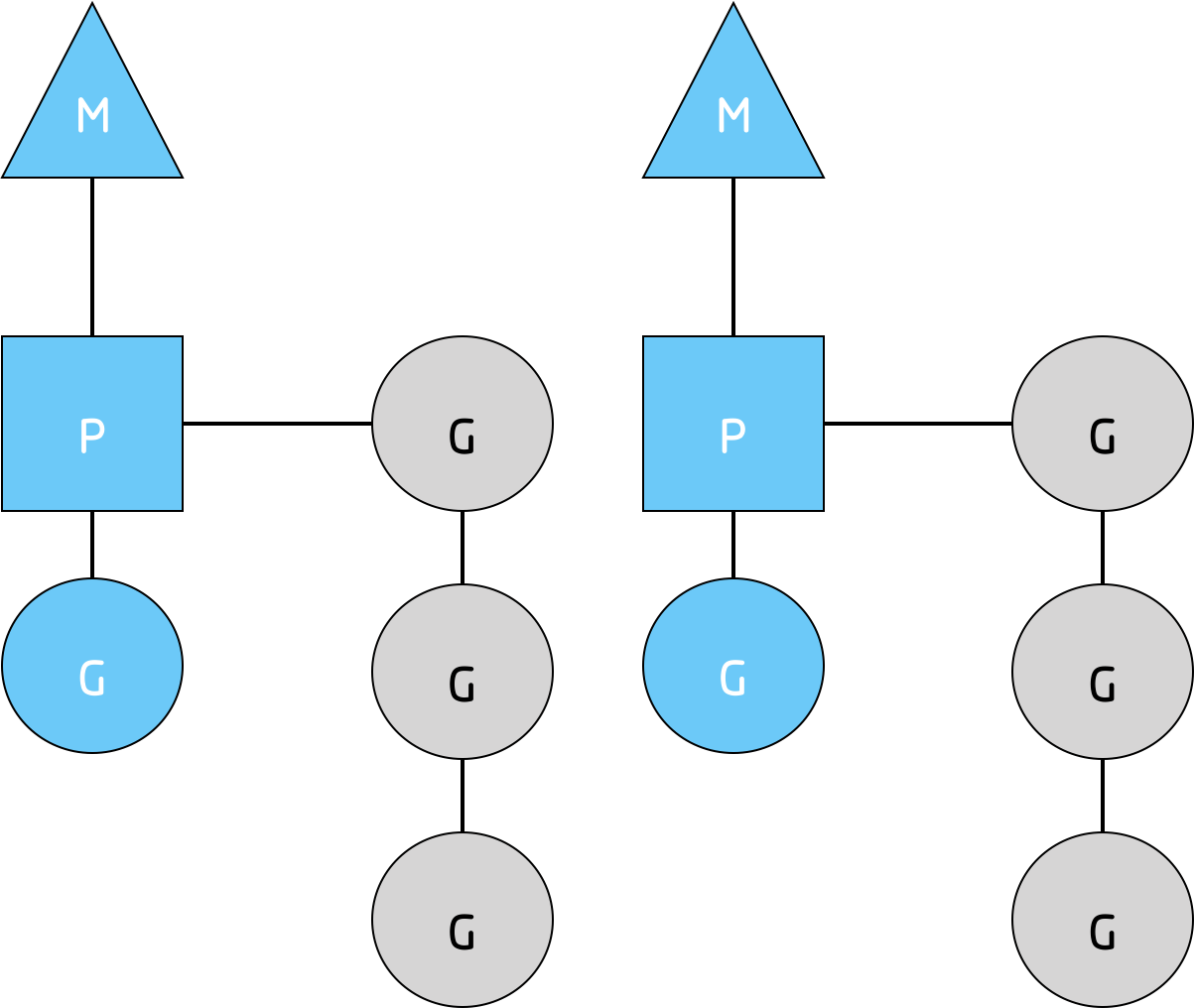
我们可以从上面的图里看到两个线程(M),每个线程都拥有一个上下文(P),每个线程都正在运行一个goroutine(G)。为了运行goroutines,一个线程必须拥有一个上下文。
上下文的数目在启动时被设置为环境变量GOMAXPROCS的值或者通过运行时函数GOMAXPROCS()来设置。通常,在你的程序执行时它不会发生变化。上下文的数目被固定的意思是,只有GOMAXPROCS个上下文正在任意时刻上运行Go代码。我们可以使用它调整Go进程的调用使其适合于一个单独的计算机,比如一个4核的PC中可以在4个线程上运行Go代码。
外部的灰色goroutines没在运行,但是已经准备好被调度了。它们被安排成一个叫做runqueue的列表。当一个goroutine执行一个go 语句的时候,goroutine就被添加到runqueue的末端。一旦一个上下文已经运行一个goroutine到了一个点上,它就会把一个goroutine从它的runqueue给pop出来,设置栈和指令指针并且开始运行这个goroutine。
为了降低mutex竞争,每一个上下文都有它自己的运行队列。在Go调度器的早期版本中,Go的调度器只有一个全全局的运行队列,并且只有一个互斥锁(mutex)来保护它。这样的设计在32核的多CPU核机器上进行性能压榨时往往会得到较差的表现。
只要有goroutine在运行,调度器就能够以一个稳定的状态运行。然而还是有一些情况能够改变这种状态。
系统调用细节
你可能想问,为什么一定要有上下文?我们能不能去掉上下文而把运行队列直接放到线程上运行?不可以,上下文存在的意义是,如果一个正在运行的线程因为一些原因需要阻塞,我们可以将其挂起并将线程上下文移交给别的线程。
另一种需要阻塞的情况是,在进行系统调用的时候。因为一个线程在进行系统调用的时候不能既执行代码又进行阻塞等待(注:一个M控制多个G,在系统调用的时候不允许其中的某个G阻塞,而另一个G运行,因为系统调用必须是原子性的)。因此我们需要将该上下文冻结以便调度。
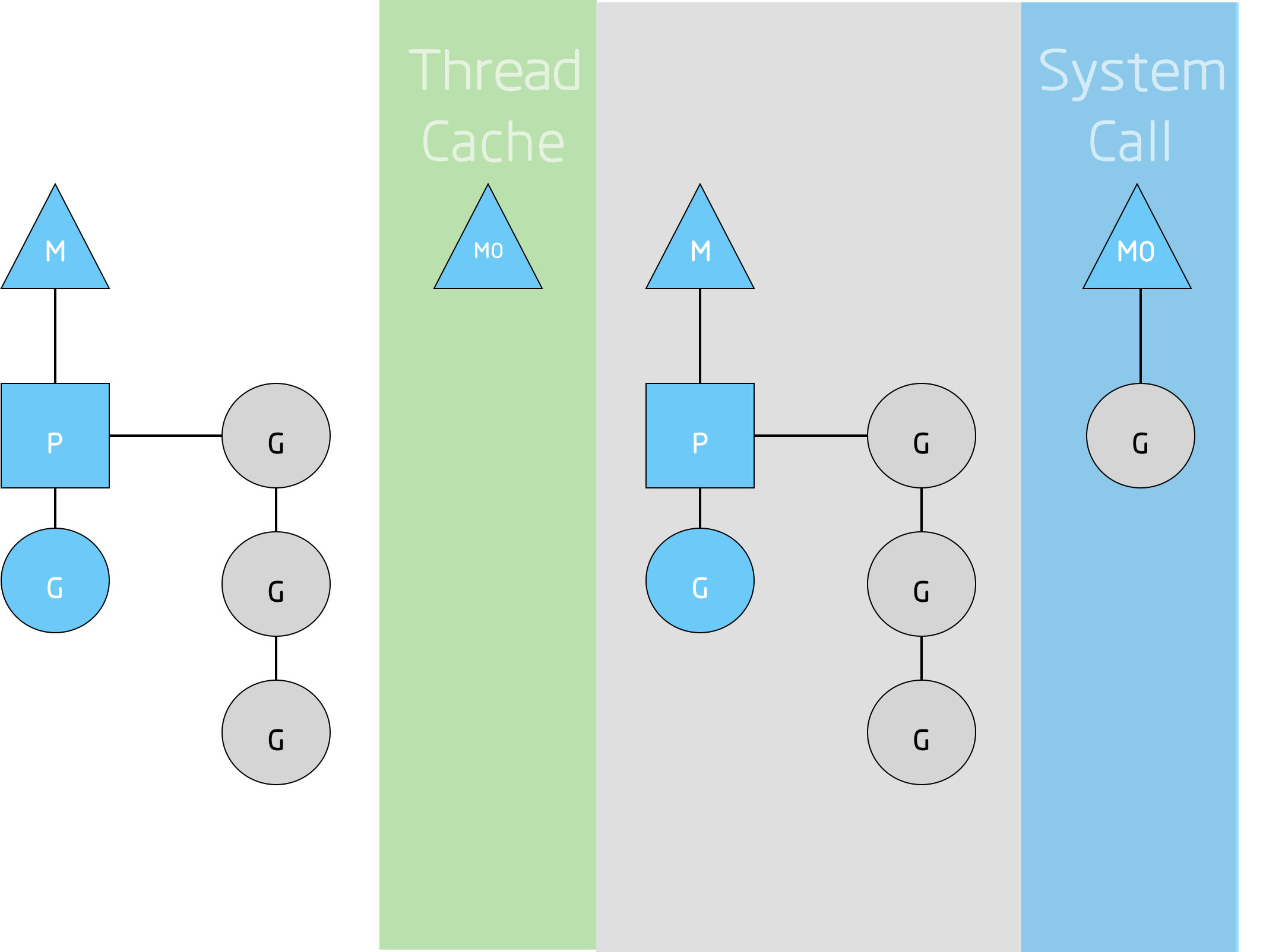
从上图我们能够看出,一个线程放弃了它的上下文以便让别的的线程可以运行G0。调度器确保预先有足够的线程来运行所有的上下文。上图中的M1 可能是仅仅为了能够处理系统调用而创建的,也可能来自一个线程池。这个处于系统调用中的线程将会一直持有导致这次系统调用这的goroutine,因为从技术层面上来说,它仍然在执行,尽管可能阻塞在OS里了。
当这个系统调用返回的时候,这个线程必须获取一个上下文来运行这个返回的goroutine。较为常见的操作是从其它线程中“偷取”一个上下文。如果“偷取”不成功,它就会把它的goroutine放回到一个全局运行队列中,然后把自己放回到线程池中然后进入睡眠状态。
这个全局运行队列是各个上下文在运行完自己的本地运行队列后获取新goroutine的地方。上下文也会周期性的检查这个全局运行队列上的以获取goroutine。如果不这样做的话,全局运行队列上的goroutines由于饥渴可能导致无法执行而终止。
Go程序要在多线程上运行就是因为要处理系统调用,哪怕GOMAXPROCS等于1。运行时使用调用系统调用的goroutines,而不是线程。
盗取工作
系统的稳定状态改变的另外一种情况是,当一个上下文运行完要被调度的所有goroutines的时。如果各个上下文的运行队列里的goroutine的数目不均衡,将会改变调度器状态。上述的情况会导致会导致一个上下文在执行完它的运行队列后就结束了,尽管系统中仍然有许多goroutine要执行。因此为了能够一直运行Go代码,一个上下文能够从全局运行队列中获取goroutine,但是如果全局运行队列中也没有goroutine了,那么上下文就不得不从其它地方获取goroutine了。
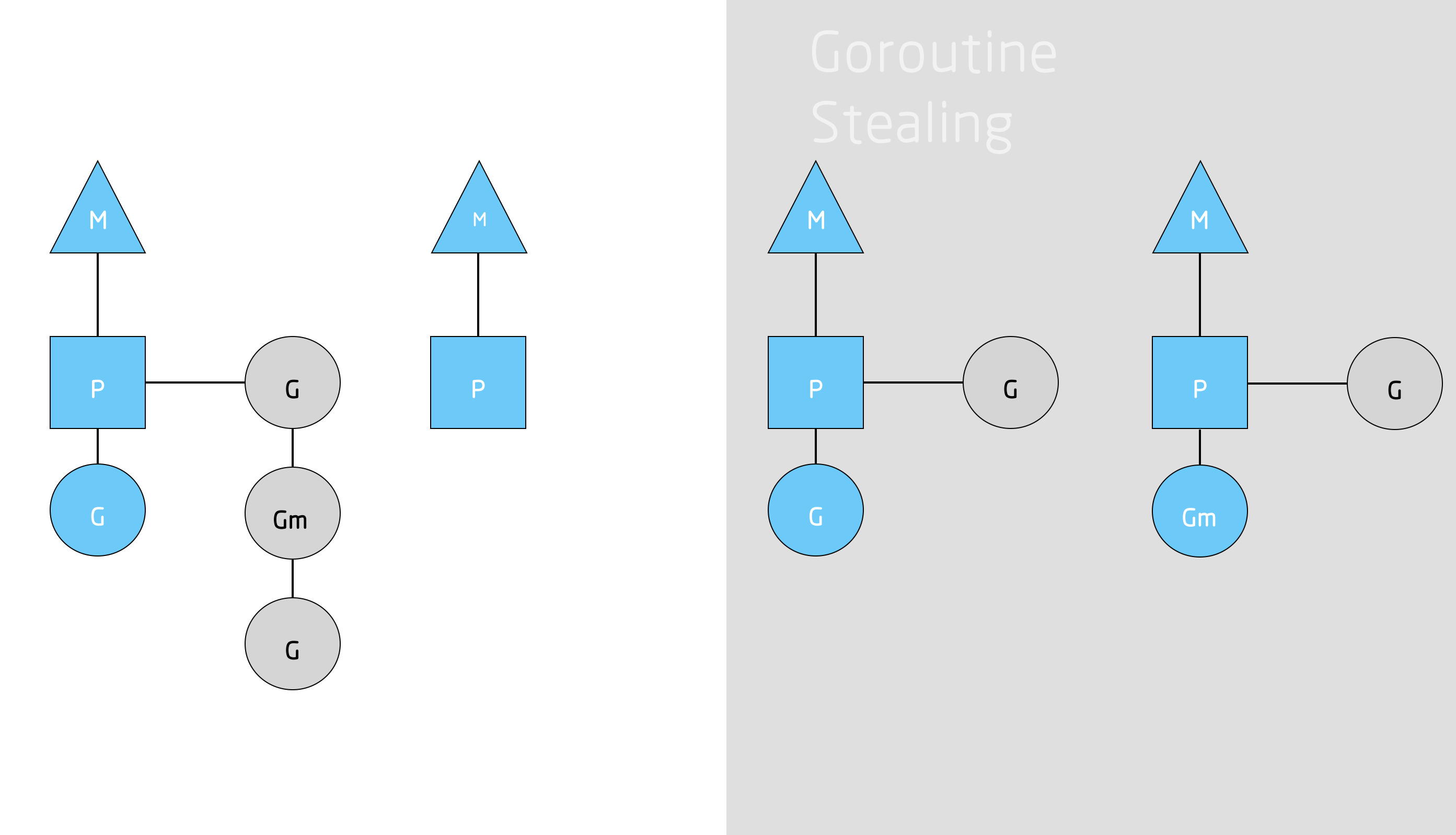
这里的“其它地方”指的是就是其它的上下文!当一个上下文完成自己的全部任务后,它就会尝试“盗取”另一个上下文运行队列中一半的工作量。这将确保每个上下文总是有活干,同时也能够保证所有的线程都处于最大的负荷。
展望
关于调度器还有许多细节,像cgo线程、LockOSThread()函数以及与系统与网络poller的整合。这些已经超过这篇文章的要探讨的范围了,但是仍然值得去深入研究。在Go运行时库里,仍然有大量有意思的创建工作要做。
原文 Daniel Morsing
翻译 Chen Quan
Releated articles: